





Fragen Sie fünf Anbieter, was ihre Kundenservice-KI leistet, und Sie werden fünf Bezeichnungen für etwas hören, das gleich klingt. Chatbot, Konversations-KI, LLM, KI-Agent. Die Begriffe werden ausgetauscht, als wären sie austauschbar, und die meisten Käufer nehmen diese Verwirrung auf, bevor sie eine Demo durchlaufen.
Die Verwirrung kostet in zweierlei Hinsicht Geld. Einige dieser Begriffe beschreiben tatsächlich unterschiedliche Funktionen, die zu einer einzigen zusammengefasst werden, sodass ein Unternehmen einen Chatbot kauft und darauf wartet, dass ein Agent erscheint. Andere sind dieselbe Funktion unter einem neueren Namen, sodass ein Unternehmen einen Aufpreis für ein umbenanntes Tool zahlt, das es bereits besaß. In beiden Fällen zeigt sich die Lücke erst in der Produktion, nachdem der Vertrag unterzeichnet wurde.
Dieser Artikel klärt die Begriffe und zieht die Trennlinie zwischen ihnen. Der Ton der Antwort ist das am wenigsten nützliche Detail, auf das man sich konzentrieren sollte. Was entscheidet, ob eine Kundenservice-KI etwas wert ist, ist, ob das System hinter der Antwort den Kunden zu einer Lösung führen kann.
Was ist Konversations-KI?
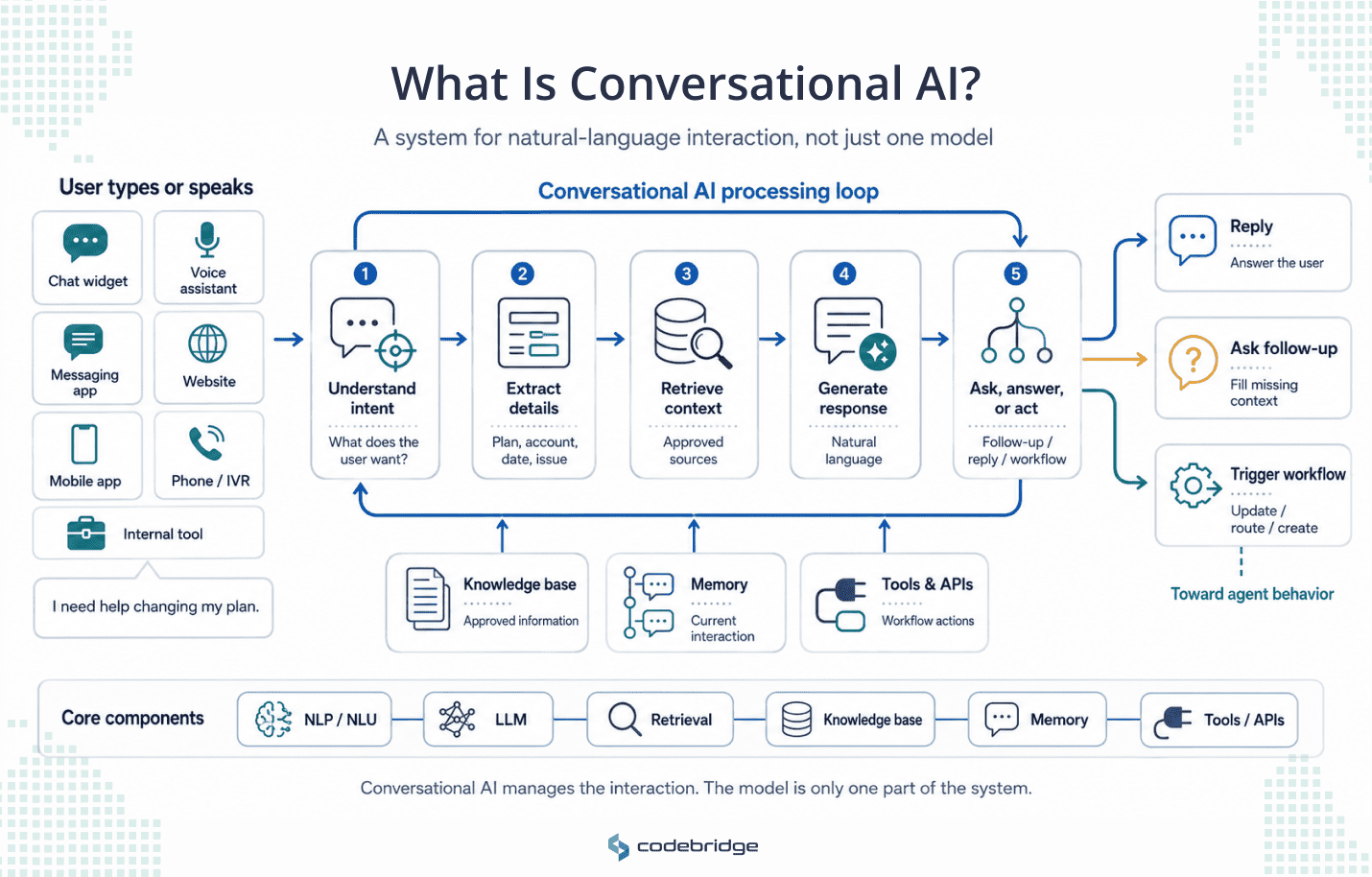
Beginnen Sie weit gefasst, bevor der Kundenservice es eingrenzt.
Konversations-KI ist Software, die KI-Techniken nutzt, um menschliche Sprache zu verstehen und durch natürliche Konversation zu antworten. Sie findet sich in Chat-Widgets, Sprachassistenten, Messaging-Apps, Websites, mobilen Apps, IVR-Telefonmenüs und internen Tools.
Der zugrunde liegende Ablauf ist systemübergreifend konsistent. Ein Nutzer tippt oder spricht, und das System identifiziert die Absicht, das, was die Person erreichen möchte. Es extrahiert die nützlichen Details aus der Nachricht. Es ruft eine Antwort ab oder generiert sie. Es kann eine Nachfrage stellen, um eine Lücke zu schließen. In leistungsfähigeren Systemen ruft es ein Tool auf oder löst einen Workflow aus, anstatt bei Worten stehen zu bleiben.
Einige verschiedene Technologien befinden sich typischerweise innerhalb dieses Kreislaufs, und jede erfüllt eine spezifische Aufgabe. Die Verarbeitung und das Verstehen natürlicher Sprache ermöglichen es dem System, Absichten zu erkennen, anstatt Schlüsselwörter abzugleichen.
Ein LLM generiert, klassifiziert und schlussfolgert über Sprache, was Antworten flexibel statt vorgefertigt hält. Eine Wissensdatenbank liefert genehmigte Informationen und unterdrückt Halluzinationen. Eine Retrieval-Schicht findet den richtigen Inhalt, bevor das Modell antwortet, und verankert die Antworten in echten Unternehmensdaten. Der Konversationsspeicher verfolgt die aktuelle Interaktion, damit sich das System zwei Runden später nicht selbst widerspricht. Tool- und API-Zugriff ermöglicht es ihm, etwas über das reine Sprechen hinaus zu tun, und hier beginnt es, sich Agentenverhalten anzunähern.
Die Quintessenz dieses Abschnitts ist, dass Konversations-KI kein einzelnes Modell ist, sondern ein System zur Verwaltung sprachbasierter Interaktionen, und das Modell ist eine Komponente darin.
Was ist Konversations-KI für den Kundenservice?
Nun gehen wir von der allgemeinen Kategorie zur Aufgabe über.
Konversations-KI für den Kundenservice ist ein System, das Kunden hilft, Antworten zu erhalten, Serviceaufgaben zu erledigen oder schneller den richtigen menschlichen Ansprechpartner zu erreichen – alles über natürliche Sprache.
Ein Kriterium bestimmt die gesamte Kategorie. Sie verdient ihren Platz nur, wenn sie den Aufwand reduziert, sei es für den Kunden oder für das Support-Team. Wenn der Kunde nach der KI-Antwort immer noch eskalieren muss, fügt die Interaktion einen Schritt hinzu, anstatt einen zu entfernen.
In der Praxis erledigt sie eine Reihe definierter Aufgaben:
- Sie beantwortet häufige Fragen, identifiziert Absichten und leitet Tickets weiter
- Sie sammelt fehlende Informationen, bevor ein Mensch eingreift, fasst Gespräche für Agenten zusammen und empfiehlt Wissensdatenbankartikel.
- Es unterstützt mehrere Sprachen, erstellt und aktualisiert Tickets, schlägt menschlichen Agenten Antworten vor, hilft Kunden, einfache Self-Service-Aufgaben zu erledigen und leitet Fälle mit angehängtem Kontext weiter.
Die Gründe, warum Unternehmen darauf zurückgreifen, sind jedem bekannt, der eine Support-Organisation leitet. Das Ticketvolumen wächst schneller als die Mitarbeiterzahl, und Kunden erwarten schnelle Antworten. Wiederkehrende Fragen fressen die Zeit der Agenten auf. Die Qualität schwankt zwischen Agenten und Kanälen. Wissen ist über Wikis und Posteingänge verstreut. Agenten benötigen einen besseren Kontext, bevor sie antworten, und das Unternehmen wünscht sich eine Abdeckung außerhalb der Arbeitszeiten einer Zeitzone, ohne in jede einzelne davon Personal einstellen zu müssen.
Das IBM Institute for Business Value beziffert dies, indem es angibt, dass Führungskräfte bis 2027 einen Anstieg von 53 % bei KI-gestütztem personalisiertem Self-Service und eine Verbesserung der Self-Service-Anrufauflösung um 47 % erwarten.
Es passt nicht überall, und das Gegenteil zu behaupten, führt zum Scheitern von Implementierungen.
Die Fälle, in denen es gut passt, haben eine gemeinsame Form: wiederkehrende Fragen mit hohem Volumen, einfache Konto- oder Produkt-Workflows, klare, richtlinienbasierte Antworten, eine saubere Wissensdatenbank, vorhersehbare Onboarding-Probleme und mehrsprachige Anforderungen.
Die risikoreichen Fälle weisen eine andere auf: unklare Richtlinien, eine unübersichtliche Ticket-Taxonomie, sensible Kontoaktionen ohne Überprüfungsschritt, ungelöste Datenqualitätsprobleme, Prozesse, die auf informellem Wissen basieren, und jede Situation, die Empathie, Urteilsvermögen, Verhandlung oder Ausnahmebehandlung erfordert.
Dieser Abschnitt wirft auch die Frage der Messung auf, obwohl die vollständige Behandlung später erfolgt. Erste Antwortzeit, Self-Service-Rate, Containment-Rate, Lösungsrate, Eskalationsrate, CSAT, Kosten pro Ticket, wiedereröffnete Tickets, manuelle Übersteuerungsrate, Fehlerrate der Automatisierung. Betrachten Sie diese Liste vorerst nur als grobe Orientierung.
Der Punkt ist, dass einige davon die Aktivität messen und andere die Lösung, und die Verwechslung beider führt dazu, dass ein Dashboard grün leuchtet, während Kunden weiterhin feststecken.
Konversationelle KI vs. Chatbots vs. LLMs vs. KI-Agenten
Diese vier Begriffe überschneiden sich, weshalb sie oft verwechselt werden. Ein Chatbot kann Teil einer konversationellen KI sein, ein LLM kann ihn antreiben, und ein KI-Agent kann ihn als Schnittstelle nutzen. Doch all das macht sie nicht zu Synonymen.
Am klarsten lassen sie sich nach ihrer Rolle unterscheiden. Ein Chatbot ist eine Schnittstelle. Ein LLM ist eine Sprach-Engine. Konversationelle KI ist ein Konversationssystem. Ein KI-Agent ist ein zielorientiertes Aktionssystem. Zwei anerkannte Definitionen verankern das obere Ende dieses Spektrums.
Deloitte definiert KI-Agenten als Denkmaschinen, die Kontext verstehen, Workflows planen, sich mit externen Tools und Daten verbinden und Aktionen zur Erreichung festgelegter Ziele ausführen.
IBM zieht die gleiche Abgrenzung von der anderen Seite, indem es sagt, dass traditionelle Chatbots regelbasiert sind und begrenzte Funktionen haben, während ein KI-Agent Workflows mit Tools entwirft, mit externen Umgebungen interagiert, Aktionen ausführt und die unvorhersehbaren Wendungen eines echten Kundengesprächs handhabt, anstatt einer festen FAQ zu folgen.
Ein einziges Beispiel macht die Unterscheidungen konkreter. Ein Kunde schreibt:
Mir wurde nach dem Upgrade meines Plans zweimal etwas berechnet. Können Sie das beheben?
- Ein einfacher Chatbot sendet eine FAQ zur Abrechnung oder leitet das Ticket an den Support weiter.
- Ein LLM-Wrapper erklärt fließend die wahrscheinlichen Gründe für eine doppelte Abbuchung und löst nichts.
- Ein konversationsfähiges KI-System erkennt das Abrechnungsproblem, fragt nach den fehlenden Details und öffnet ein Ticket.
- Ein KI-Agent prüft das Konto, bestätigt die doppelte Abbuchung, bereitet den Rückerstattungsworkflow vor und führt ihn entweder innerhalb eines genehmigten Limits aus oder eskaliert den Fall mit allen benötigten Informationen für den Menschen.
Derselbe Satz vom Kunden, aber das sind vier sehr unterschiedliche Ergebnisse, und nur eines davon führt dazu, dass die Abbuchung tatsächlich bearbeitet wird.
Wo Chatbots enden und KI-Agenten beginnen
Ein Chatbot bewährt sich, wenn das Problem vorhersehbar ist. Ein KI-Agent wird nützlich, wenn das Problem Kontext, Tools, Entscheidungen oder die Bewegung durch einen Workflow erfordert.
Dies sollte sorgfältig formuliert werden, denn der Fehler hierbei ist, einen Chatbot zu kaufen und Agenten-ähnliches Verhalten von ihm zu erwarten. Chatbots sind nach wie vor wirklich gut bei einer definierten Reihe von Aufgaben: FAQ-Antworten, einfache Weiterleitung, grundlegende Fehlerbehebungsbäume, Abfragen des Bestellstatus bei Integration, Lead-Erfassung, Terminplanung, Anleitung zur Passwortrücksetzung, Navigation im Hilfe-Center und das Sammeln von Informationen vor einer Übergabe. Innerhalb dieses Rahmens sind sie schnell, kostengünstig und zuverlässig.
Sie stoßen an ihre Grenzen. Der Kunde stellt eine mehrstufige Frage. Die Antwort hängt von kontospezifischen Daten ab. Das Problem erstreckt sich über mehrere Systeme. Der Kunde hat bereits Self-Service versucht und eskaliert frustriert. Der Fall beinhaltet eine Richtlinienausnahme. Der Kunde ist wütend oder ein wichtiger Kunde. Das Problem erfordert eine Aktion statt einer Erklärung. Oder der Chatbot kann sich nicht erinnern, was der Kunde vor einem Kanal gesagt hat. Drängt man einen Flow-basierten Bot in eine dieser Situationen, stockt er höflich.
Ein KI-Agent beginnt dort, wo das System den Kunden und seinen Kontext identifizieren, das Supportziel verstehen, die relevanten Richtlinien- oder Kontodaten abrufen, den nächsten Schritt entscheiden, Tools aufrufen oder Aktionen vorbereiten, eskalieren kann, wenn sein Vertrauen sinkt, den Kontext für eine menschliche Übernahme bewahren und verfolgen kann, ob das Problem tatsächlich gelöst wurde. Diese letzte Fähigkeit ist diejenige, die Käufer oft übersehen und später bereuen.
Produktionsnachweise untermauern die Unterscheidung. Eine Forschungsarbeit aus dem Jahr 2026 von Nubank, einer Bank mit über 100 Millionen Nutzern, berichtet über den Aufbau von Kundensupport-Agenten in diesem Umfang und stellt unverblümt fest, dass produktionsreife Agenten koordinierte Arbeit in den Bereichen Evaluierung, Kontext-Engineering, Training und Online-Messung erfordern, nicht nur einen cleveren Prompt. Bei einer Implementierung zur Kartenauslieferung führte groß angelegtes A/B-Testing zu einer Verbesserung des transaktionalen Net Promoter Score um 37 Prozentpunkte und einer Steigerung der Self-Service-Rate um 29 Prozentpunkte gegenüber früheren Agentenversionen.
Die Studie weist auch auf ein Ergebnis hin, das die gesamte „wie menschlich klingt es“ Debatte neu gestalten sollte. In den meisten Anwendungsfällen lag die KI-Zufriedenheit innerhalb weniger Prozentpunkte der von erfahrenen menschlichen Agenten. Der Ton war nie der Engpass. Das System um den Ton herum war es.
Gartner erwartet, dass die Autonomie weiter zunehmen wird. Es wurde prognostiziert, dass agentische KI bis 2029 80 % der gängigen Kundenserviceprobleme ohne menschliches Eingreifen lösen wird. Ob diese Zahl pünktlich erreicht wird, ist weniger wichtig als ihre Richtung, die genau auf die in diesem Abschnitt beschriebene Verschiebung vom Chatbot zum Agenten hinweist.
Dies ist auch der Grund, warum ernsthafte Implementierungsarbeiten selten am Chatfenster beginnen. Bei einem Codebridge-Projekt ist die erste Frage, was der Kunde am Ende des Gesprächs erledigt haben sollte.
Codebridges Leitfaden für KI-Agenten im Kundenservice verfolgt diesen systemzentrierten Ansatz durch Implementierung, Workflows, Schutzmechanismen und ROI. Der Rest dieses Artikels konzentriert sich auf einen Teil davon und beantwortet die Frage, was hinter dem Gespräch existieren muss, damit überhaupt etwas funktioniert.
Was hinter dem Gespräch existieren muss: Der siebenstufige Lösungs-Stack
Das Chatfenster ist das sichtbare Zehntel des Systems. Ob eine Kundenservice-KI erfolgreich ist, entscheidet sich in den darunterliegenden Schichten, jenen, die kein Kunde sieht und die die meisten Käufer nicht ausreichend spezifizieren. Wir nennen dies den Seven-Layer Resolution Stack, die Gesamtheit der Dinge, die entworfen werden müssen, bevor eine Konversation zu einer Lösung werden kann.
Ebene 1, Kundenkontext. Das System benötigt das Kundenprofil, den Tarif, die Produktnutzung, den Kontostatus, frühere Tickets und die Historie des aktuellen Problems. Überspringt man dies, fragt die KI nach Informationen, die der Kunde bereits gegeben hat, was der schnellste Weg ist, in den ersten dreißig Sekunden das Vertrauen zu verlieren.
Ebene 2, Wissen. Hilfezentrum, Richtliniendokumente, Produktdokumentationen, Support-Playbooks, Fehlerbehebungsanleitungen, Compliance-Regeln, Rückerstattungs- und Gutschriftenrichtlinien. Der Fehlerfall hier ist eine selbstbewusste Antwort, die auf einer Richtlinie basiert, die sich im letzten Quartal geändert hat. Antworten auf eine vertrauenswürdige, aktuelle Quelle zu stützen, ist die Lösung.
Ebene 3, Systemzugriff und Integrationen. CRM, Ticketing, Abrechnung, Auftragsverwaltung, Kontoverwaltung, Produktdatenbank, Terminplanung, interne Admin-Tools. Ohne diese kann die KI eine Lösung beschreiben, aber nicht ausführen, und jede echte Aktion muss immer noch von einem Menschen von Grund auf neu begonnen werden.
Ebene 4, Kompetenzgrenzen. Dies ist die Ebene, die die meisten Teams implizit lassen, und hier konzentriert sich das Betriebsrisiko. Das System benötigt explizite Regeln dafür, was es beantworten, vorschlagen, vorbereiten, ausführen und was immer an eine Person weitergeleitet werden muss. NISTs KI-Risikomanagement-Framework macht den gleichen Punkt in der Governance-Sprache: menschliche Rollen und Aufsicht sollten bewusst definiert werden, und Mensch-KI-Konfigurationen können von vollständig autonom bis vollständig manuell reichen.
Codebridges jüngster Artikel legt ein umfassenderes Autoritätsmodell dar, vom Nur-Lese-Zugriff über vorbereitete Aktionen bis zur vollständigen Ausführung. Die Kurzfassung für diese Diskussion: Entscheiden Sie im Voraus und schriftlich, was das System beantworten, vorbereiten, ausführen und was es an einen Menschen übergeben darf.
Ebene 5, Eskalationslogik. Vertrauensschwellen, Hochrisikothemen, verärgerte Kunden, VIP-Konten, Rückerstattungs- und Rückbuchungsstreitigkeiten, alles, was rechtlich, medizinisch, finanziell oder compliance-relevant ist, und wiederholte Fehlerschleifen. Das Muster, dem entgegengewirkt werden muss, ist der Kunde, der eindeutig eine Person benötigt und im Gespräch mit der Software stecken bleibt. Eine saubere Eskalation trägt den gesamten Kontext mit sich, was das Thema von ist.
Ebene 6, Evaluierung und Tests. Testen Sie anhand realer historischer Tickets, vergleichen Sie die KI-Ausgabe mit menschlichen Expertenantworten, führen Sie den Betrieb im Schattenmodus durch, forcieren Sie Grenzfälle und messen Sie Halluzinationen, ungelöste Probleme und wiederholte Kontakte vor dem Start. Das Nubank-Papier erklärt direkt, warum sich diese Ebene auszahlt: die Qualität der Evaluierungs-Pipeline bestimmt direkt, wie schnell Sie das System verbessern können. Eine schwache Evaluierungs-Pipeline begrenzt Ihre Iterationsgeschwindigkeit, egal wie gut das Modell ist.
Schicht 7, Monitoring nach dem Start. Antwortqualität, Eindämmung gegenüber echter Lösung, Eskalationsqualität, Kundenzufriedenheit, wiederholte Beschwerden, Kosten pro gelöstem Ticket, Modelldrift, fehlerhafte Integrationen, veraltetes Wissen. Qualität verschlechtert sich schleichend. Ohne Monitoring ist der erste Hinweis, den Sie erhalten, ein Churn-Report, dann ist der Schaden bereits Monate alt. Siehe: Artikel zur Agenten-Observability.
Wie das aussieht, wenn es richtig umgesetzt ist
Die Belege von Codebridge für diese Schichten stammen nicht aus Support-Bot-Projekten, was der nützliche Teil ist. Dieselbe Ingenieurskunst zeigt sich überall dort, wo ein System eine Live-Konversation führen und darauf reagieren muss, und sie lässt sich direkt auf den Kundenservice übertragen.
Auf einer Echtzeit-KI-Nachhilfeplattformwar Latenz der Feind. Eine drei- bis fünfsekündige Pause zwischen dem Sprechen eines Schülers und der Antwort des Avatars unterbrach den Rhythmus, der den Einzelunterricht effektiv macht, und die Schüler brachen die Sitzung mittendrin ab. Der Umbau reduzierte die Sprachstart-Latenz auf unter eine Sekunde und hielt die durchschnittlichen Antwortzeiten unter zwei Sekunden. Die Arbeit an der Kontinuität ist für den Support noch wichtiger.
Jede Sitzung erstellt ein automatisiertes Transkript und speichert ihren Zustand, sodass ein Schüler, der die Verbindung verliert, mit vollem Kontext fortfahren kann, anstatt von vorne zu beginnen, und eine „Chat fortsetzen“-Funktion jede vergangene Lektion dort wieder öffnet, wo sie endete. Übertragen Sie das auf eine Support-Warteschlange, und es ist der Unterschied zwischen einem Agenten, der sich daran erinnert, was der Kunde bereits erklärt hat, und einem, der ihn dazu bringt, es noch einmal zu sagen, was Schicht 1 ist, die wie vorgesehen funktioniert.
Eine Multi-Agenten-Plattform für Ingenieur-Recruiting zeigt die gesteuerte Produktionsseite des Stacks. Aufbauend auf einem LangGraph-Orchestrator, der spezialisierte Agenten koordiniert, agiert das System eigenständig nur, wenn sein Vertrauen 90 % übersteigt. Unterhalb dieser Grenze leitet es den Fall an einen Menschen weiter, und Entscheidungen in der Endphase bleiben designbedingt bei einer Person, was Schicht 4 und Schicht 5 konkretisiert. Seine Agenten sind durch Retrieval auf die unternehmenseigenen Einstellungsstandards geerdet, was sie davon abhielt, Bewertungskriterien zu erfinden – das Recruiting-Äquivalent eines Support-Bots, der eine nicht existierende Rückerstattungsrichtlinie zitiert.
Vor dem Launch bewertete das Team historische Fälle neu und maß eine Übereinstimmung von etwa 90 % zwischen dem System und erfahrenen Ingenieuren – dieselbe Disziplin der Expertenbewertung, die Nubank für Schicht 6 beschreibt. Im Betrieb verfolgt Observability-Tooling jede Agentenentscheidung, was Schicht 7 ist. Autoritätsschwellen, Retrieval-Grounding, Pre-Launch-Evaluierung und Entscheidungsverfolgung sind genau die Kontrollen, die ein Kundenservice-Agent benötigt, bevor er ein Live-Konto berührt.
Zusammen decken die beiden Projekte den gesamten Stack ab. Die Nachhilfeplattform trägt Kundenkontext und Gesprächskontinuität. Die Recruiting-Plattform trägt Integrationen, Autorität, Eskalation, Evaluierung und Monitoring. Keines davon ist eine Kundenservice-Implementierung, und das muss es auch nicht sein. Die Disziplinen sind übertragbar.
Selbst entwickeln, kaufen oder anpassen: Welche Art von Kundenservice-KI benötigen Sie wirklich?
Die glaubwürdige Antwort ist, nicht alles selbst zu entwickeln. Viele Unternehmen sollten zuerst eine Plattform kaufen. Maßgeschneiderte Arbeit rechnet sich, wenn der Workflow, die Daten, Integrationen oder Geschäftsregeln die Standardeinrichtung unzureichend machen.
Ein Plan für die ersten 30 Tage
Wenn Sie anfangen, geht es bei der Arbeit eher darum, die Realität abzubilden, als einen Anbieter auszuwählen.
Woche 1: Die Support-Realität abbilden. Exportieren Sie Ihre Top 50 bis 100 Ticketkategorien. Markieren Sie, welche davon repetitiv und hochvolumig sind, welche Kontodaten benötigen und welche menschliches Urteilsvermögen erfordern. Vermerken Sie, wo Kunden heute den Self-Service abbrechen.
Woche 2, wählen Sie einen risikoarmen Workflow aus. Gute erste Kandidaten: Passwort- und Zugangsunterstützung, Liefer- und Bestellstatus, Abonnement- und Planfragen, Onboarding-Hilfe, einfache Fehlerbehebung, Ticketzusammenfassung, Vorschläge zur Agentenunterstützung. Sparen Sie sich die schwierigen Fälle für später auf: Rückerstattungen, Rechnungskorrekturen, alles Medizinische, Rechtliche oder Finanzielle, Kontoauflösung, emotional aufgeladene Beschwerden und Compliance-intensive Aufgaben.
Woche 3, definieren Sie das Betriebsdesign. Nennen Sie die vertrauenswürdigen Wissensquellen, die Daten, die das System lesen kann, die Tools, die es aufrufen kann, die Eskalationsregeln, die Vertrauensschwellen, die menschlichen Überprüfungspunkte und die Erfolgsmetriken. Dies ist der Sieben-Schichten-Lösungs-Stack, angewendet auf einen Workflow.
Führen Sie Tests mit historischen Tickets durch, vergleichen Sie mit menschlichen Antworten, testen Sie Grenzfälle, betreiben Sie den Shadow-Modus, überprüfen Sie die Eskalationen und legen Sie einen Startschwellenwert fest, an den Sie sich tatsächlich halten werden. Fazit
Die Begriffe werden sich weiter vermehren, und Anbieter werden sie weiterhin verwischen. Die gültige Abgrenzung ist dieselbe, mit der dieser Artikel begonnen hat. Konversationelle KI ist die Schnittstelle. Der Wert im Kundenservice kommt vom System dahinter. Ein Chatbot wird zu einem KI-Agenten, sobald das System Kontext halten kann, auf relevante Tools zugreifen kann, weiß, was es tun darf, und den Fall an eine Person übergibt, bevor Schaden entsteht.
Wenn konversationelle KI in Ihrem Support-Workflow mit echten Kundendaten, internen Tools, Produktlogik oder Eskalationsregeln verbunden werden muss, erfolgt die entscheidende Arbeit, bevor die erste Antwort überhaupt generiert wird. Codebridge hilft Teams, von einer KI-Idee zu einem funktionierenden System zu gelangen: den Workflow abzubilden, die Grenzen festzulegen, die Integrationen zu erstellen und zu messen, ob die Lösung den Support tatsächlich verbessert.
Beginnen Sie mit dem Pillar Guide oder besprechen Sie den Umfang mit uns .










Heading 1
Heading 2
Heading 3
Heading 4
Heading 5
Heading 6
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Block quote
Ordered list
- Item 1
- Item 2
- Item 3
Unordered list
- Item A
- Item B
- Item C
Bold text
Emphasis
Superscript
Subscript








