





It's 2:47 AM. Your phone has buzzed seventeen times in the last nine minutes, and the on-call engineer in Bangalore is on her third Slack thread trying to work out whether the GPU memory alert in the inference cluster is the cause or a symptom of the rate-limiter timeouts in the gateway. By the time someone touches a kubectl command, twenty-three minutes have passed. The fix itself takes ninety seconds. If you've shipped any production AI framework in the last two years, you know this shape — and you also know that "buy an AI agent" is not, by itself, the answer.
An NOC team that put numbers on this exact pattern called it out cleanly:
"27% of organizations report more than half of their MTTR is wasted time — the biggest contributor being team engagement, communication, and collaboration. The manual parts."
Erik Anderson, Dev.to (autonomous NOC operations write-up)
That's the trap most teams walk into when they evaluate self-remediating frameworks: they optimize the ninety-second fix and leave the twenty-three minutes of coordination untouched. This playbook is for the engineer who has been told "go install a self-healing agent" and needs to know what to actually do on Monday.
KEY TAKEAWAYS
Coordination is the dominant MTTR cost. Self-remediating frameworks deliver outsized wins when they target alert correlation and triage handoff, not just code-level fixes.
Scope boundaries determine ROI more than model quality. Teams reporting MTTR cuts from 45 minutes to 5-18 minutes paired their agents with runbooks, SLOs, and explicit autonomy envelopes.
Reconciliation latency is the hidden tail. A self-healing agent is only as fast as the loop that accepts its fix; in GitOps shops, interruptible reconciliation is now table stakes.
Self-healing is a capability, not a product. Install-only deployments produce zero MTTR improvement; instrumented deployments produce 40-70% reductions in manual interventions.
Faster MTTR can mask strategic drift. If your remediation loop runs faster but your alert volume keeps rising, you've automated a treadmill, not solved the underlying noise problem.
The Hidden Problem: You're Automating the Wrong Minute
Senior practitioners tend to picture MTTR as a single number — the wall-clock time from "page fired" to "graph green again." That number averages over four very different phases: detection, correlation, decision, and execution. Google's SRE Workbook frames this in its treatment of toil and its incident management chapter: the cost driver in mature systems isn't fix difficulty, it's the coordination tax — paging the right person, correlating signals across systems, deciding who owns the next step.
The diagram below illustrates how MTTR actually decomposes inside a typical AI framework operations team:
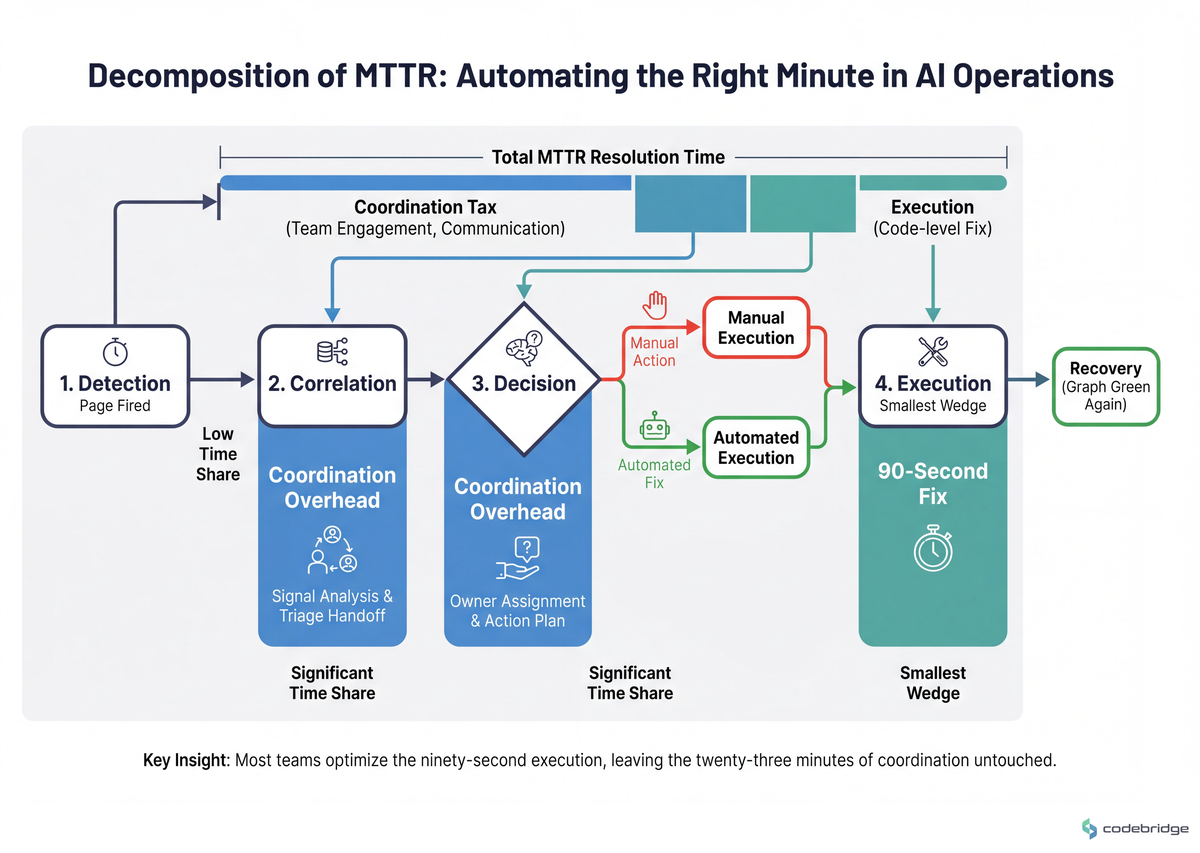
If your framework's "self-remediation" only touches the execution phase, you've sped up the smallest wedge. The fintech and NOC teams reporting genuinely large drops in MTTR (45 → 5-18 minutes) are the ones who pushed automation upstream into correlation and decision.
Real Stories From the Field
An AWS Builders post measured its DevOps agent against a clean pre-agent baseline — useful because most vendor case studies skip the baseline:
"After configuring the DevOps agent, MTTR dropped to 18 minutes, alert noise reduced to 35 alerts per incident, 40% of incidents were auto-diagnosed, and 20% were auto-remediated."
AWS Builders community post, Dev.to
The line that gets buried in that result: "install alone produces zero MTTR improvement." The 18-minute number happened because the team paired the agent with executable runbooks, defined SLOs, and clear service ownership. Those three preconditions are the difference between a working playbook and a slide.
A Capital One write-up on alert clustering pointed at the same lever from a different angle:
"By using NLP and pattern detection, they can cluster related alerts and recommend solutions in real-time, reducing triage time by 50%."
Ranjan, Dev.to (AI in DevOps pipelines write-up)
Notice what's automated and what isn't: clustering and recommendation, not execution. The 50% triage cut comes from collapsing N alerts into one decision, not from auto-applying fixes. If you're choosing where to spend your first quarter of self-remediation work, this is the highest-ROI starting point.
The Pattern: Where the Wins Actually Come From
Across the cases above and the engagements we've run, three things separate the teams that report 40-70% MTTR reductions from the teams that report "we installed the agent and… nothing really happened":
- They automated correlation before remediation. Cluster alerts, dedupe, attach service ownership — then decide what to remediate.
- They drew the autonomy envelope explicitly. "The agent can restart pods and roll back to the previous revision. It cannot scale clusters, change IAM, or modify model weights." Written down. Reviewed quarterly.
- They instrumented the agent itself. The agent's decisions, escalations, and false-positive rate are first-class telemetry — not buried in vendor dashboards.
The architectural shape of a working self-remediation loop is shown below:
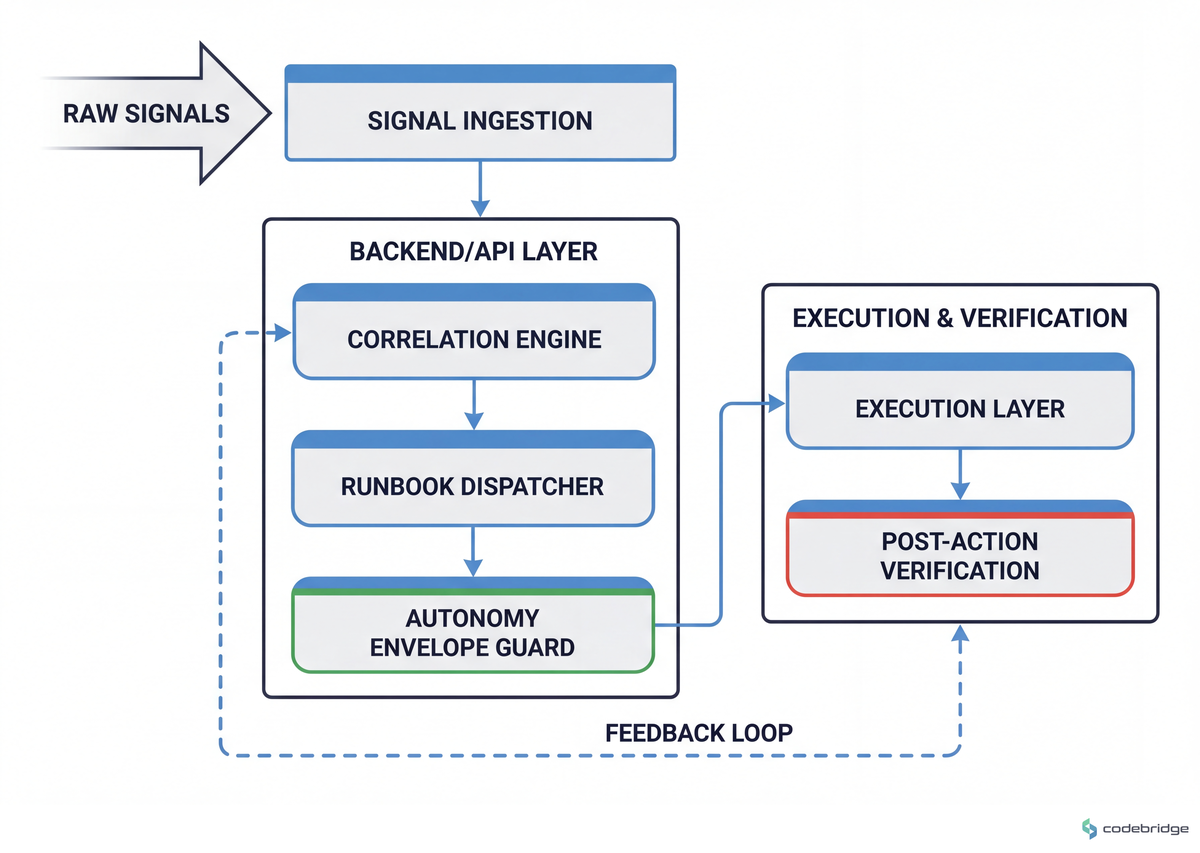
One framing worth being honest about: a Reddit cybersecurity practitioner reviewing AI-vendor pitches reminded the field that local optimization can mask strategic drift —
"Cool. So… we're polishing the same turd, just with a bigger GPU."
r/cybersecurity, Reddit
Faster MTTR on a rising alert curve is a treadmill. The framework matters less than what you decide to do with the headroom it buys you — which is the spirit behind step 7 below.
The Playbook: Five Days, Seven Steps
Step 1 — Measure your real MTTR breakdown
What to do: For your last 20 incidents, log time-to-detect, time-to-correlate, time-to-decide, time-to-execute as separate fields.
What good looks like: You can answer "what % of MTTR is coordination" in one query. If detection + correlation + decide is >60% of MTTR, the agent's job is upstream of execution.
Common failure mode: Reporting only full MTTR. You can't optimize what you can't decompose.
Step 2 — Start with correlation, not auto-fix
What to do: Deploy the agent in advisory mode against alert clustering and ownership routing first. No write actions yet.
What good looks like: Alerts-per-incident drops by ≥50% within 4 weeks (Capital One's reported floor; treat it as a target, not a ceiling).
Common failure mode: Skipping straight to auto-remediation. The agent then auto-fixes the wrong service because nobody fixed the ownership map.
Step 3 — Draw the autonomy envelope in writing
What to do: Produce a one-page document listing exactly which actions the agent may take autonomously, which require human approval, and which are forbidden. Tie each to a service tier.
What good looks like: A new engineer can read the page and tell you, in 60 seconds, whether the agent is allowed to roll back a deployment to the payments service.
Common failure mode: "The agent uses good judgment." You will regret that sentence at 3 AM.
Step 4 — Wire executable runbooks to detection signals
What to do: Each high-frequency alert source gets a machine-readable runbook (YAML, JSON, or code-as-runbook). Manual prose runbooks don't count.
What good looks like: ≥80% of P2/P3 incidents map to a runbook the agent can actually invoke. The remaining 20% are tracked as "needs runbook" tickets.
Common failure mode: Runbooks live in Confluence as paragraphs of advice. The agent can read them, but can't execute them — so it escalates to a human, defeating the point.
Step 5 — Make reconciliation interruptible
What to do: If you run GitOps, audit your reconciliation loop's behavior on in-flight failures. Newer reconcilers (Flux 2.8+, Argo with appropriate sync waves) support cancelling stuck health checks the moment a fix is committed.
What good looks like: When you push a fix to a failing rollout, your reconciler picks it up within seconds — not after the full timeout.
Common failure mode: Optimizing detection and remediation while your reconciliation loop adds 3-10 minutes of latency to every recovery.
Step 6 — Instrument the agent itself
What to do: Treat the agent as a first-class service. Track decisions/min, false-positive rate, escalation rate, and the "rolled back the agent's action" rate.
What good looks like: You can answer "did the agent help or hurt this week?" with a number, not a vibe. False-positive rate <5% on auto-remediated incidents is a reasonable initial gate.
Common failure mode: Trusting the vendor dashboard. It will not show you the actions you needed to undo.
Step 7 — Use the headroom to lower the alert ceiling
What to do: Every quarter, take the time the agent gave you back and spend half of it on root-cause work that reduces alert volume. The other half is yours.
What good looks like: Total alerts/week trending down, not just MTTR/alert. Otherwise you've automated a treadmill — the cybersecurity practitioner above will be right about you.
Common failure mode: Treating the headroom as pure productivity gain. Six months later, alert volume has doubled and the agent is running at capacity.
The two most common deployment shapes — install-only versus instrumented — are summarized below:
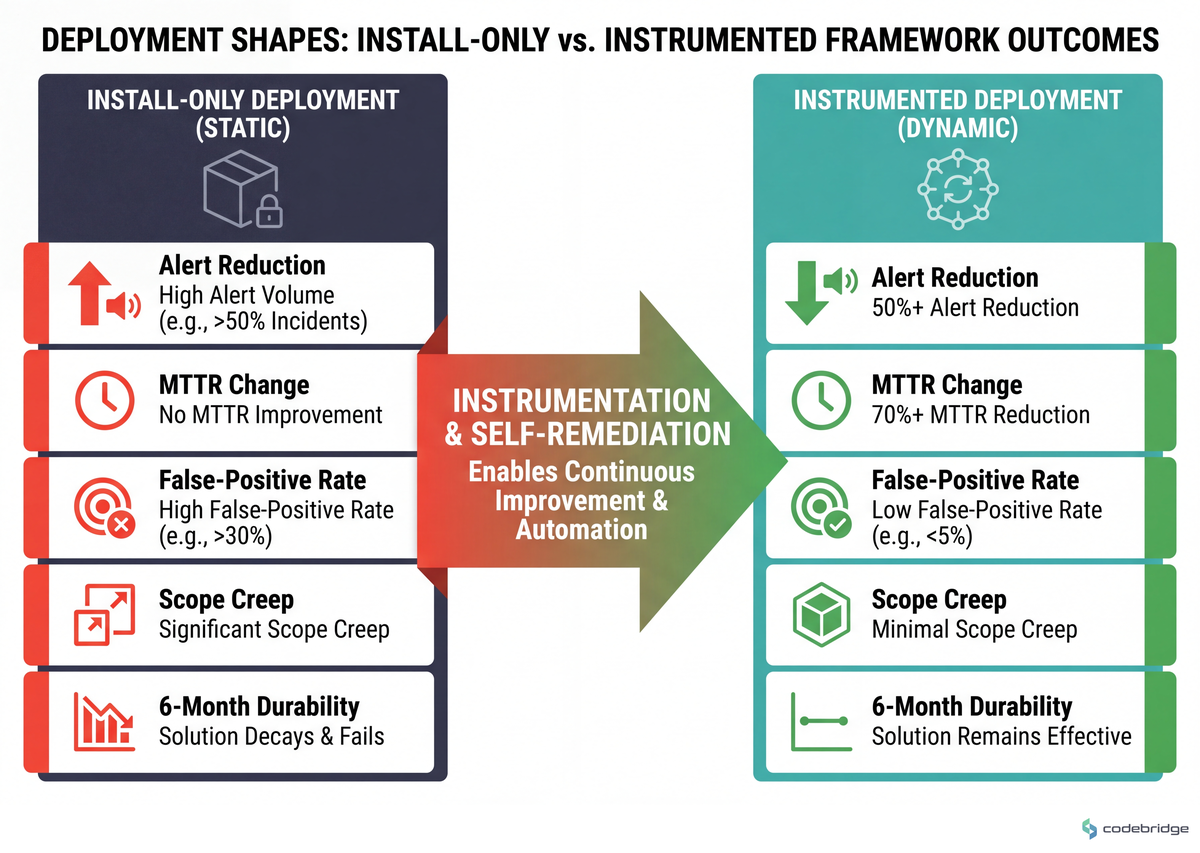
Close: Your Week
That 2:47 AM scene at the top of this article is solvable, but not by the install-only path. Tomorrow morning, run Step 1: pull your last 20 incidents and decompose MTTR into detection, correlation, decision, and execution. By Wednesday, finish Step 2 and Step 3 — agent in advisory mode against correlation, autonomy envelope written down. By Friday, Step 4 has at least three executable runbooks wired in and Step 5 has confirmed your reconciliation loop isn't silently eating recovery time. Steps 6 and 7 are next sprint's work, but they only pay off if 1-5 are real.
If you do nothing else this week, do this one thing in the next 30 minutes: open your incident tracker, pick the five longest MTTR incidents from the last quarter, and write down — for each — what percentage of the resolution clock was spent in Slack threads before anyone touched the system. That single number tells you whether you're shopping for the right kind of agent.
If your top-five incidents show coordination >50% of MTTR, buying a faster execution engine is the wrong purchase. You need correlation and routing first.
Diagnostic Checklist: Score Your Self-Remediation Readiness
Run these against your current system. Three "yes" = healthy starting position. Five "yes" = at risk; rebuild before scaling autonomy. Seven "yes" = your install will produce zero measurable MTTR improvement.
Can you produce, today, the coordination-vs-execution share of your last 20 incidents' MTTR? No = +1
Do more than 30% of your alerts lack a clear single service owner mapped in code or config? Yes = +1
Are your runbooks prose paragraphs in Confluence rather than machine-executable artifacts? Yes = +1
Is the agent's autonomy scope ("what it may touch, what it may not") undocumented or "left to its judgment"? Yes = +1
Does your reconciliation loop wait for full health-check timeouts before accepting a pushed fix? Yes = +1
Do you lack a tracked metric for the agent's false-positive rate and rolled-back-action rate? Yes = +1
Has your weekly alert volume been flat or rising despite MTTR improvements over the last quarter? Yes = +1
Stuck between "we installed it" and "it's actually working"?
Talk to our team about auditing your self-remediation loop full — from alert correlation through autonomy envelope to reconciliation latency.
REFERENCES












Heading 1
Heading 2
Heading 3
Heading 4
Heading 5
Heading 6
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Block quote
Ordered list
- Item 1
- Item 2
- Item 3
Unordered list
- Item A
- Item B
- Item C
Bold text
Emphasis
Superscript
Subscript








