



Three months into shipping an agent system, the bug reports converge on one phrase: "the agent forgot what we were doing." The model is fine. The prompts are fine. The model card promises 200K context. And yet, by step seven of a long task chain, the agent is solving a different problem than the one you gave it.
An engineer building production agents named the failure mode on dev.to and called it Agentic Amnesia. The fix they landed on was structural, not a prompt tweak:
"This 'external state' acts as a rhythmic beat that keeps the context window focused on the finish line." The post unpacks how they prepend a running summary — original goal, completed steps, current step, remaining steps — to every LLM call, treating context as a budget you actively manage rather than a window you fill.
imaginex, dev.to
If you're shipping anything more autonomous than a single-turn chatbot in 2026, you will meet this failure mode. The good news: the playbook for avoiding it is short, sequential, and doable in a week.
KEY TAKEAWAYS
Agentic AI is the fastest-growing technology trend by momentum, per McKinsey's 2025 outlook — the competitive window for shipping reliable agent systems is now, not next quarter.
The bottleneck is problem decomposition and context discipline, not model capability. Switching from Sonnet to Opus does not fix a vague goal.
Production agents need an external state ledger — a status summary prepended to every LLM call to counteract context drift across long task chains.
Multi-agent orchestration has lowered the barrier for solo founders to ship full-stack software, shifting the bottleneck from coding fluency to problem framing.
Hardware spend follows agent ambition: AI-driven compute demand is rising exponentially, and inference costs become a board-level number once agents loop.
The Hidden Problem: Agent Loops Don't Fail Loudly
Agent failures don't crash. They drift. The agent returns a polite, plausible answer to a question you didn't ask. By the time you notice, you've burned tokens, time, and — if the agent had write access — production state.
The macro picture says this matters more every quarter. McKinsey's 2025 Technology Trends Outlook ranks agentic AI as the trend with the highest momentum-score increase in their cross-trend index — combining foundation models with autonomous workflow execution.
That growth has a hardware shadow. The same outlook documents a sharp spike in patents for application-specific semiconductors — the chips, networking, and memory that make agent loops affordable — and reports that demand for compute is rising exponentially. Our reading: if your agent system runs hot, you're paying for both the model and the silicon shortage. Reliability is now a P&L lever.
Agent reliability is no longer an engineering quality bar — it's a P&L line. Every drifted run is a token bill, an engineer-hour, and a missed delivery, and the cost compounds with concurrency.
Real Stories: How Drift Looks in the Wild
Three vignettes from the field — all from public sources, each illustrating the same architectural truth from a different angle.
The compiler that took two weeks (and one decomposition pass)
A widely-cited experiment described on dev.to set a research team loose with multiple Opus 4.6 agents on a vague brief: build a C compiler. The first attempts stalled — the goal was too abstract for any single agent to hold across a session. Once the team broke the goal into precisely-defined subtasks with explicit inputs, outputs, and acceptance criteria, the trajectory changed:
"Two weeks later, it could run on the Linux kernel — 100,000 lines of working Rust code, without a single line written by a human."
imaginex, dev.to
The lesson the post pulls out — and that matches what we see in client engagements — is that problem decomposition is the new core engineering skill. The agent doesn't replace the architect; it replaces the implementer. If the architecture is vague, the agent will produce vague work, very fast.
The surgeon who shipped a platform solo
A second dev.to writeup describes a thoracic surgeon — no software background — who shipped a full-stack platform (blog, analytics, multi-agent orchestration on the backend) by running 67 sequential Claude Code sessions:
"67 autonomous agent sessions later, I shipped a full-stack platform with blog, analytics, and multi-agent orchestration."
jpeggdev, dev.to
The headline reads as an AI-hype story. The actual lesson is more useful for a founder: the bottleneck moved from can you code to can you frame the problem. Robinhood CEO Vlad Tenev, summarizing the shift in a 2025 Forbes panel, put it like this:
"AI Will Fuel A New Era Of Entrepreneurial Execution."
Vlad Tenev, CEO, Robinhood
Translated to your roadmap: a domain expert with good problem-framing now ships faster than a competitor with five engineers and bad problem-framing. The competitive moat has moved upstream.
The drift you'll see first
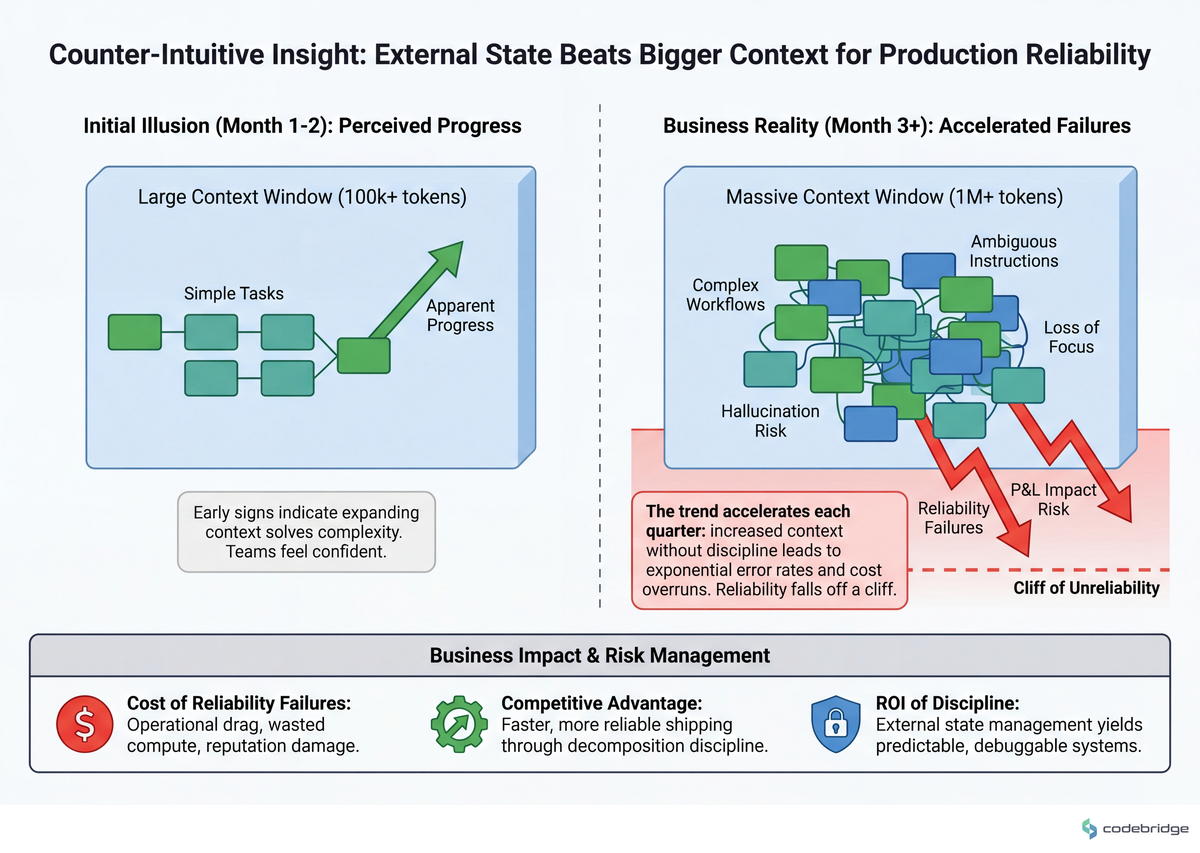
Imagine a mid-size SaaS team running a customer-support triage agent. The first weeks would look fine — tickets routed cleanly. By the third week, a product manager might notice that the agent had drifted into "summarizing" the user's question instead of routing it. By month two, the team would be debating whether to fine-tune. The actual fix would be upstream: the agent's prompt would have accumulated three rounds of "also do X" without anyone removing the original routing instructions, and context drift would do the rest. The pattern we want to illustrate is that drift usually shows up as scope creep in the agent's identity, not as a model failure.
The Pattern: External State Beats Bigger Context
The teams that ship reliable agent systems share three disciplines, in order of importance: (1) they decompose vague goals into testable subtasks before any code runs, (2) they treat the context window as a budget actively managed by an external state ledger, and (3) they choose an orchestration shape (pipeline, swarm, supervisor) deliberately rather than letting it emerge.
The disciplines compound. Without (1), you give the agent an impossible job. Without (2), the agent forgets the job mid-execution. Without (3), you can't tell which agent did the forgetting.
The macro signal supports this. Deloitte's 2025 CEO guide to tech trends reports heavy investment by core systems providers to make simpler, agile data access the default across the organization. Our reading is that this widens the gap between teams with decomposition discipline and teams without it, because the former can absorb the new capabilities and the latter just adds them to the mess.
The architecture below shows what an external-state-ledger loop looks like in practice:
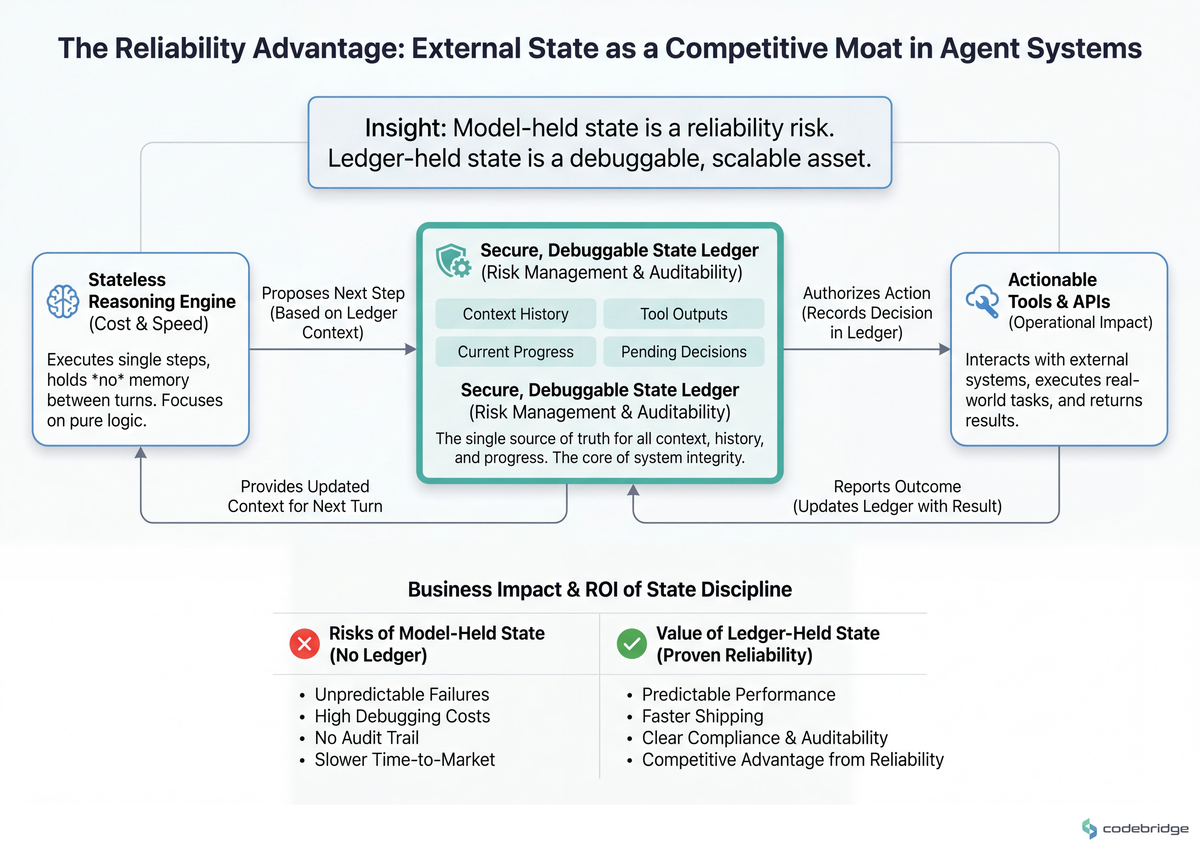
The Playbook: Five Steps, One Week
If you have an agent system in production (or about to be), these are the steps in order. The point is sequence: doing step 4 before step 1 is how teams end up with elaborate observability on top of an unsolvable problem. The flow below maps the week:
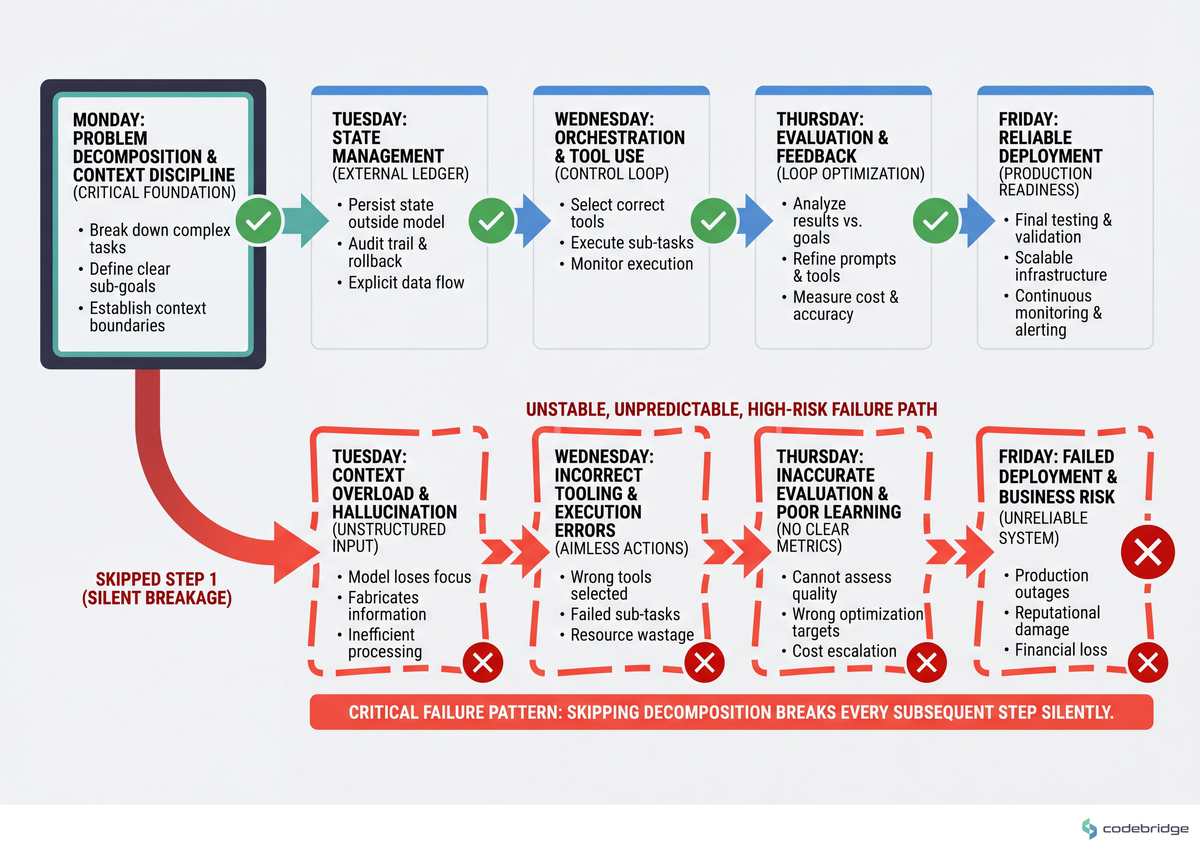
Step 1 — Write the goal as a one-sentence acceptance test
What to do: For each agent (or each top-level agent invocation), finish the sentence "this run was a success if and only if ___." If you can't finish it in 25 words or fewer, decompose the goal first.
What good looks like: "This run was a success if and only if the inbound email is classified into one of {refund, billing, technical, escalate} AND a draft reply is created in the user's draft folder." Testable, scoreable, bounds the agent's identity.
Common failure mode: Goals that contain "and also handle…" or "should ideally…" — those are two goals or a vague one, not a specification.
Step 2 — Build the external state ledger
What to do: Implement a small structured object — JSON, a Postgres row, anything — that tracks {original_goal, completed_steps, current_step, remaining_steps, blockers}. Prepend a serialized snapshot to every LLM call in the loop.
Concrete pattern: Cap the snapshot at ~600 tokens. If your agent is on step 18, you don't include all 17 prior step transcripts — you include the goal, a one-line summary per completed step, the current step in full, and the remaining steps as a list. The model spends its attention on what matters now.
Measurable signal: If you can't reconstruct what an agent was trying to do by reading the last serialized snapshot alone, the ledger is too thin. If snapshots are hitting 2K+ tokens, it's too thick.
Step 3 — Choose an orchestration shape on purpose
What to do: Pick one of three default shapes and write down why:
- Pipeline — agent A's output is agent B's input, fixed order. Use when the task decomposes cleanly into stages (extract → transform → validate → publish).
- Supervisor — one orchestrator agent assigns subtasks to specialist agents and aggregates results. Use when the task is heterogeneous and needs routing.
- Swarm — multiple agents work in parallel on independent subtasks, results merged at the end. Use when subtasks are truly independent and latency matters.
Threshold: if you find yourself wanting two of these shapes inside one product, that's a signal to split into two products with different SLAs, not to invent a fourth hybrid shape.
Step 4 — Instrument for drift, not for cost
What to do: Cost dashboards are easy and lagging. Drift dashboards are harder and leading. Two metrics matter: (a) goal-restatement accuracy — does the agent's first action in step N still align with the original goal? (b) action-type histogram — is the agent doing more "summarize" actions over time when its job is "route"?
Worked example: Sample 50 runs per week. Have a second LLM call (or a human) score "did this run's final action serve the original goal?" on a 0/1 basis. If your weekly score drops below 0.85, freeze the prompt and find the regression before shipping anything else.
Step 5 — Set a kill threshold per agent run
What to do: Define a hard cap — token budget OR step count OR wall-clock time, pick one — that aborts a runaway agent and surfaces it for human review. No agent runs unbounded in production.
Threshold to start with: 25 steps, 50K tokens, or 10 minutes — whichever hits first. Tighten with data. The cost of a wrong abort is one human review; the cost of an unaborted runaway agent is, in our experience, an order of magnitude higher — sometimes including data corruption.
The two operating modes side by side:
Close: Your Week
The failure mode that opened this article — Agentic Amnesia — isn't waiting for a model upgrade to disappear. It's a discipline problem with a discipline fix, and the fix slots into a normal week.
Tomorrow morning, open the most recent failed (or weird) agent run and write down — in one sentence — the original goal that run was supposed to serve. If you can't, you've found Step 1's homework. Wednesday, add the external state ledger to one agent loop and watch the next 10 runs. Friday, set the kill threshold and ship it behind a feature flag.
The 30-minute artifact: a single text file titled agent-acceptance-tests.md with one sentence per agent your system runs. If that file doesn't exist by end of day Tuesday, no orchestration framework, model upgrade, or eval suite will save the roadmap.
Need a second pair of eyes on your agent architecture before the kill-threshold debate consumes a sprint?
Talk to our team about a one-week agent-reliability audit.
Diagnostic Checklist
Run these against your current system. Score one point per Yes:
Can you write the success criterion for each agent step in one sentence of 25 words or fewer? Yes / No
Does every LLM call in your agent loop receive a serialized status summary (original goal, completed steps, current step, remaining steps) at the top of its prompt? Yes / No
Did your last documented agent failure have a postmortem that explicitly named the original goal vs. what the agent actually did? Yes / No
Is there a hard kill threshold (token budget, step count, or wall-clock cap) that aborts a runaway agent before it touches production state? Yes / No
Can a non-engineer reading 50 lines of your agent log describe — without you in the room — what the agent was trying to accomplish? Yes / No
If you swap the underlying model (Opus → Sonnet → Haiku), does anything in your code break beyond the model identifier string? Yes / No
Do you sample at least 30 production runs per week and score them for goal alignment, not just success/failure? Yes / No
Scoring: 6-7 Yes = healthy agent system. 4-5 Yes = drift risk; prioritize the gaps. 0-3 Yes = your roadmap is whatever the agents have decided to do this week.
REFERENCES













Heading 1
Heading 2
Heading 3
Heading 4
Heading 5
Heading 6
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Block quote
Ordered list
- Item 1
- Item 2
- Item 3
Unordered list
- Item A
- Item B
- Item C
Bold text
Emphasis
Superscript
Subscript









