



The brownfield modernization playbook: what to do when "scale-first" architecture and AI agents both miss the point
You've inherited the.NET 4.x service that pays your bills. Your team scoped the migration to.NET 8 — the runbook looks fine, the timeline is two sprints, your senior engineer signed off. Three weeks in, a dev surfaces a problem in standup: the logging library you've used since 2017 isn't compatible with the target runtime. Two days after that, an old XML parser starts emitting empty strings instead of throwing — silently corrupting downstream records in staging. A developer writing on dev.to about exactly this scenario put it cleanly:
"By spotting it early, we avoided weeks of troubleshooting and rewrote only the affected parts — dependencies often hide surprises."
Jay M., dev.to
If you've led a brownfield project in the last twelve months, the shape of that story is familiar. What's new in 2026 is that there's now a second, equally seductive failure mode standing right next to "I forgot to audit dependencies": "I asked the AI agent to handle it." Both lead to the same kind of post-mortem.
KEY TAKEAWAYS
AI agents fail predictably on brownfield code. Tools optimized for greenfield generation regenerate logic instead of integrating with existing architecture, and the failure mode surfaces around the two-week mark on a single feature.
Most production systems run nowhere near their architected scale. A boring monolith on a single VPS comfortably handles 700-1000 RPS — far more than most B2B SaaS workloads ever reach.
Modular boundaries pay before microservices do. Splitting a billing module from patient records inside the same monolith lets a team migrate and test in isolation without committing to a distributed system.
Dependency audits are the cheapest insurance in any migration. Categorize every library as migrate-as-is, rewrite, or extra-testing before the first line of new code is written.
The hidden problem: brownfield is not what your tools assume
The dominant 2026 narrative — that AI agents collapse engineering effort by an order of magnitude — holds on greenfield. It does not hold on the systems most of you actually run. Revenue-generating codebases are 5-15 years old, layered with quiet workarounds, and contain at least one module that nobody on the current team wrote. Both your AI tools and your "let's modernize" instinct are calibrated for a world your codebase doesn't live in. Microsoft's own .NET porting guidance spends most of its surface area on assessment and dependency mapping for this exact reason — the runtime jump is the easy part.
The result is two parallel mistakes. The first is over-architecture: teams reach for distributed systems, message queues, and NoSQL stores before their traffic justifies any of it. The second is over-delegation: teams hand brownfield refactors to coding agents that only know how to start fresh. The diagram below contrasts the two reflexes against the pragmatic middle path.

Calling either reflex wrong is too strong. Both are responses to genuine pressure — investor decks asking about scale, AI vendors asking why your velocity hasn't doubled. The cost is hidden: you spend the budget that should have funded a dependency audit on a Kafka cluster that processes ten messages a minute. According to the 2024 Stack Overflow Developer Survey, the majority of professional developers now use or plan to use AI coding assistants — which makes the over-delegation failure mode systemic, not anecdotal.
Three patterns we keep seeing in 2026
Across recent engagements with technology teams running brownfield modernization, the same three patterns surface in nearly every kickoff. They're not exotic. They're the failure modes you'll recognize from your own quarterly reviews.
The first pattern shows up wherever scale anxiety drives architecture. A solo SaaS operator on dev.to ran the math most teams never run: their boring stack — Postgres, REST, a React monolith, one VPS — handled real production traffic without breaking a sweat. The line that lands hardest:
"700–1000 RPS on a single VPS is the reality check most developers need to hear. We architect for Google-scale when we haven't even reached 'One VPS scale' yet."
the_nortern_dev, dev.to
The post isn't claiming this is right for every workload. It documents one operator's measured load on one box. That's the entire point: the writer ran the numbers. Most teams don't.
The second pattern shows up where AI tools meet existing code. A developer on r/vibecoding spent two weeks iterating with Cursor on a brownfield project before concluding the obvious:
"It solves problems by generating new code, not by understanding existing architecture."
Reddit r/vibecoding
This is a description of what the tool optimizes for, not a complaint. Greenfield generation is a known-good problem with bounded inputs. Brownfield integration requires comprehension of existing constraints, conventions, and the seventeen reasons that one weird if-statement is actually load-bearing. Vibe-coding tools handle the first; they don't handle the second.
The third pattern is more granular but instructive: agentic dev tooling itself leaks context between commands. A developer documenting an OpenCode + Conductor workflow on dev.to noted that Conductor's slash commands like /commit ignore attached Linear issues on the first invocation:
"When you run commands with Conductor it tends to ignore any attached issues — you have to attach them, let it fail, then attach again on the new message."
chand1012, dev.to
The lesson generalizes past Conductor: agentic tools in 2026 are good enough to be useful and brittle enough to need workarounds. If your modernization plan assumes the agent maintains task context across commands, you'll discover otherwise on a Friday afternoon.
The pattern: brownfield rewards comprehension, not generation
The teams that ship brownfield modernization on schedule share one habit: they spend disproportionate time on comprehension before they touch code. Dependency audits. Module-boundary mapping. Identifying which modules are migrate-as-is versus rewrite versus extra-testing. They treat this as engineering work, not pre-work, and they don't outsource it to an agent.
The reason is structural. Both over-architecture and vibe-coding fail in the same way: they substitute a generic model of "what good systems look like" for the specific model of "what THIS system actually does". Distributed-systems thinking ships you Kafka before you need durability guarantees. Agentic coding ships you a parallel implementation before you've understood the existing one. Both bypass the comprehension step.
The same pattern shows up at the architecture level. A team running ~50 RPS doesn't need event sourcing. A team running ~5000 RPS might. The teams that ship modernization on time write down the actual number first, then design backward from it. The teams that don't write down the number end up with whatever architecture was trending on Hacker News the quarter they started.
The five-step brownfield modernization playbook
This is the sequence we run on every brownfield engagement that involves a runtime upgrade, framework migration, or module extraction. It's deliberately short. The diagram below shows the dependency between steps — each one feeds the next, and skipping any one of them costs more than the time it saves.
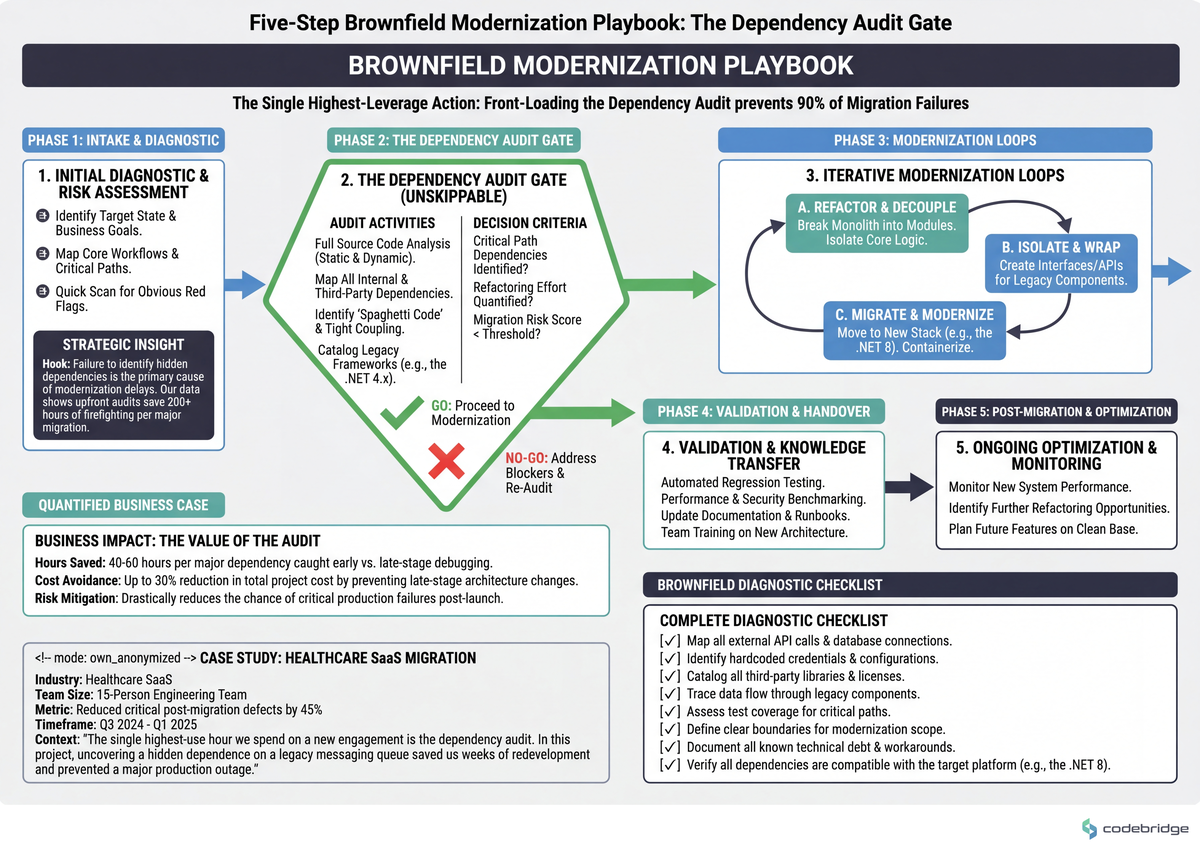
Step 1 — Run a dependency audit and categorize every library
Before any migration code is written, produce a spreadsheet with one row per direct dependency. Three columns: target-version compatible (Y/N), license-compatible (Y/N), maintenance status (active/abandoned). Categorize each into migrate as-is, rewrite, or extra testing required. Threshold: if more than 15% of direct dependencies fall into "rewrite", scope a separate dependency-replacement project before the migration. Common failure mode: trusting the framework's automated compatibility report. It checks API surface, not behavior — that's how a perfectly "compatible" XML parser starts returning empty strings instead of throwing.
Step 2 — Measure your actual production load before you change architecture
Capture peak RPS, p95 latency, and database connection count from the last 30 days. Write the numbers down. Threshold: if peak RPS is under 500 and p95 latency is under 200ms, no architectural change is justified by scale — the migration is a runtime upgrade, not a redesign. Threshold: if peak RPS sits between 500 and 2000, evaluate vertical scaling and connection-pool tuning before any horizontal change. Distributed-systems complexity only starts paying for itself on typical web workloads above ~2000 sustained RPS.
Step 3 — Modularize the monolith before you migrate it
Extract the modules with the clearest boundaries first. Concrete pattern: identify the module with the lowest cross-cutting dependency count (count imports in and out), give it its own namespace and its own test suite, and migrate it independently. The healthcare team in the dev.to thread above did this with billing-versus-patient-records: one monolith, internal lines drawn, billing migrated first while patient records stayed untouched. Measurable signal: if your team can't deploy the extracted module without running the full integration suite, the boundary isn't real yet — keep refining before you migrate.
Step 4 — Use AI agents on bounded subtasks, not on architecture
Agents are net-positive on tasks with three properties: well-defined input, well-defined output, verifiable result. That's mechanical refactors, test generation for legacy code paths, type-annotation backfills, and codemods. Threshold: if a task takes more than two iterations of "no, that's not what I meant", the task isn't bounded enough — break it down or do it yourself. Worked example: a single-namespace API rename across 200 call sites is bounded; "modernize the auth flow" is not. The first is an hour with an agent; the second eats two weeks before you notice the agent regenerated logic instead of integrating with what was there.
Step 5 — Set "stop migrating" criteria up front
Define what done means before you start. Concrete pattern: three exit criteria — runtime version reached, dependency audit at zero "rewrite" entries remaining, and production p95 latency within 10% of pre-migration baseline. Measurable signal: if the team is six weeks past the planned end date and exit criteria still aren't written down, the project has slipped from migration into rolling refactor. That's a different project with different ROI math, and stakeholders should know.
Closing the loop
Back to the dependency-audit story we opened with: the team caught the incompatible logging library and the broken XML parser early because they ran the audit before they shipped. They rewrote the affected parts and avoided weeks of troubleshooting. That outcome wasn't luck. It was the single hour of categorization work that everyone is tempted to skip.
Tomorrow morning: open a spreadsheet, list every direct dependency in the system you're about to modernize, and tag each one as migrate-as-is, rewrite, or extra-testing. Wednesday: instrument the production system and write down peak RPS, p95 latency, and database connection count from the last 30 days — three numbers, one paragraph in the project doc. By Friday: identify the single module with the lowest cross-cutting dependency count and scope its extraction as the first migration unit. If you can't finish all three by Friday, the gap is telling you something about how much modernization budget is being absorbed by processes other than modernization.
Modernizing a system you didn't write?
Talk to our team about scoping a dependency audit and modular-extraction plan for your stack.
Diagnostic checklist: is your modernization plan grounded?
Can you state your system's peak RPS, p95 latency, and database connection count from memory, without opening a dashboard? Yes / No
Is there a written dependency table where every direct dependency is tagged migrate-as-is, rewrite, or extra-testing? Yes / No
Is there at least one module in your monolith you could deploy independently without running the full integration suite? Yes / No
Are your AI agents currently scoped to bounded mechanical tasks (codemods, type backfills, test generation) rather than architectural decisions? Yes / No
Do you have three written exit criteria for the migration that any teammate could quote back to you in standup? Yes / No
If you've adopted distributed components (message queues, event stores, NoSQL), do your measured traffic numbers actually justify them? Yes / No
Is there an agentic-tool workaround documented in your team's runbook (slash command failures, context loss, retry patterns)? Yes / No
Scoring: 6-7 yes = your modernization plan is grounded. 4-5 yes = audit the gaps before the next sprint planning. 0-3 yes = stop coding, start measuring.
REFERENCES













Heading 1
Heading 2
Heading 3
Heading 4
Heading 5
Heading 6
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Block quote
Ordered list
- Item 1
- Item 2
- Item 3
Unordered list
- Item A
- Item B
- Item C
Bold text
Emphasis
Superscript
Subscript









