





The thesis of this article is: a scaling vector database startup's strategic engineering roadmap is won or lost by two disciplines — deliberate capacity allocation across horizons, and a hard buy/build/partner default — both of which fail silently while the founder-CTO is still the smartest person in every code review.
The brilliant CTO who is behind on every timeline
Matt Watson, a startup operator writing on LinkedIn, opens his piece on the founder-CTO scaling crisis with a picture every one of us recognizes from the inside.
"They have a brilliant CTO who can architect elegant solutions — and they're behind on every timeline." Pull requests pile up waiting for approval. Code quality issues mount. Frustration grows across the team, customers, and stakeholders. The technical brilliance at the top has become the bottleneck underneath.
Matt Watson, "The Hidden Scaling Crisis Every Startup CTO Must Overcome", LinkedIn
If you are a founder-CTO running a vector database startup in 2026, this picture is sharper than usual. The substrate you sell on — disk-based ANN, hybrid retrieval, embedding versioning — is itself moving every quarter. You cannot just ship features against a fixed primitive. You are reasoning about a roadmap whose underlying assumptions get revised on the cadence of arXiv preprints, while also being the person who approves every non-trivial PR.
KEY TAKEAWAYS
Horizon allocation drift is the default failure mode. Most CTOs accidentally route ~95% of capacity to keeping the lights on, then complain engineering never invests in the future.
Build-by-default is more expensive than founders model. A wrong "buy" is reversible in a week; a wrong "build" sucks ~5% of your team forever.
Vector-DB roadmaps need migration discipline, not feature discipline. Embedding model upgrades behave like database migrations — dual-write, parallel index, cutover.
The founding CTO bottleneck is a structural problem with a structural fix. Hire a complementary VP of Engineering before the PR queue, not after.
Time-to-hire for AI specialists is now a roadmap input, not a hiring problem. Buffer it explicitly or your launches will slip into the next fiscal.
The hidden problem: the substrate moves while you're roadmapping it
Two architectural shifts have hardened into defaults in production vector database stacks during the last year. The first is that hybrid search — semantic plus keyword, with multi-vector retrieval — has crossed from "what the careful teams do" to "what production RAG looks like". The second is that embedding model upgrades are being treated as database migrations with parallel indexing and dual-write patterns, not as "let's just re-index over the weekend".
For founder-CTOs, this is not academic. It means two of your highest-use features — retrieval quality and continuous embedding improvement — are no longer differentiators you build, they are table stakes you maintain. The honest reading:
"Vector databases are no longer optional infrastructure for AI-native systems. They are part of your core data layer."
NeuralStackMS, Vector Database Architecture & Scaling Guide (2026)
Read against the bottleneck story above, this implies something uncomfortable. Our reading is that the founder-CTO's time is being pulled in two opposite directions at once: deeper into the substrate (because the substrate is your product), and further out toward team scaling (because the team is now the thing that ships). Without an explicit capacity model, both lose.
Real stories from the field
On r/startups, a non-technical founder of a two-person B2B startup — one paying customer, eight to ten in onboarding — described the exact moment the gap started showing.
"I don't want to wake up one day with a major issue that could've been avoided with better practices." Bugs were beginning to appear in critical user flows because requirements were getting forgotten, pull requests piled up, and code quality issues mounted as they moved past pure MVP toward investor conversations.
Early-stage founder, Reddit r/startups
The thread doesn't reveal how it ended — the most recent posts are still the founder asking which lightweight framework to put in place. But the recognition pattern is what matters: this founder noticed the gap one investor pitch before it became a fundraising blocker. Most of us notice it one investor pitch after.
Truong Phan, writing on dev.to about a CTO playbook for build-versus-buy, puts a number on the cost of the default that vector DB teams fall into hardest — building infrastructure that already exists.
"Most companies build 50% and spend 30% of engineering capacity rebuilding things that have $50/month vendors." Default to buy 80%, build 20%, partner the rest. Build only when it's your unique value prop, vendor cost pays back in under 18 months, compliance demands it, or vendor outage kills your business. A wrong "buy" is reversible; a wrong "build" sucks 5% of your team forever.
truongpx396, The CTO Playbook: From Best Builder to Best Bet, dev.to
Vector database teams have a particular weakness here. The substrate is interesting, the papers are exciting, the open-source primitives are tantalizing — and so we build our own re-rankers, our own eval harnesses, our own observability layers. Three of those four were $50/month vendors the day we started.
The pattern: capacity allocation, then buy/build discipline, then ownership
Forbes Tech Council's reporting on enterprise AI scale-up captures the operational version of this lesson precisely.
"The model becomes someone else's problem, issues show up late, priorities conflict and real-world performance suffers." Pilots used hand-picked data, only a few integration points, and manual oversight that didn't survive production. Once deployed, ownership fragmented across data engineering, platform, product, risk, legal, security, and operations.
Forbes Tech Council, March 2026
For a vector database startup, the analog is brutal. Your customers' AI products are themselves moving from pilot to production. If your roadmap doesn't explicitly model how their re-indexing, hybrid search adoption, and embedding versioning will look on day 90, you are about to find out which of your features were a demo and which were infrastructure.
The visualization below sketches the capacity-allocation trap most founder-CTOs walk into without naming it:
The diagram below shows how the three engineering horizons compete for the same head count, and where most teams drift over the course of two to three quarters:
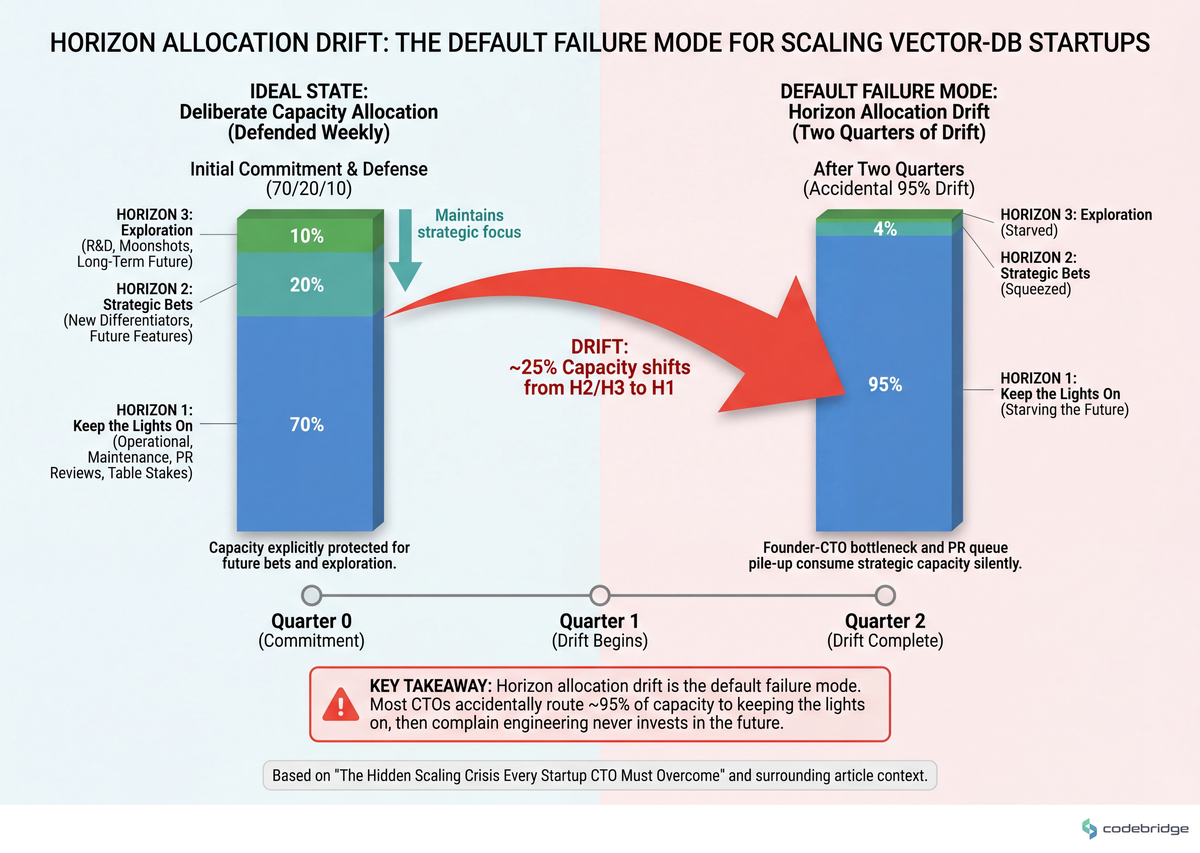
The playbook: five steps for the next two quarters
Step 1 — Write down your horizon allocation, then defend it weekly
What to do: Commit on paper to a 70/20/10 (or 60/30/10) split across Horizon 1 (operate and incrementally improve today's product), Horizon 2 (the three to five strategic bets that define the next 12 months), and Horizon 3 (exploration). Review the actual time-tracked split every Friday for four weeks.
What good looks like: By week four, your sprint planning rejects at least one "urgent" Horizon-1 request per sprint because it would push allocation past 75%.
Common failure mode: You write the allocation, get pulled into a customer escalation, and never look at the spreadsheet again. If your last three sprints all rounded to 95% Horizon-1, the allocation is decorative. Per the buy/build playbook, this is exactly the state where strategic bets starve.
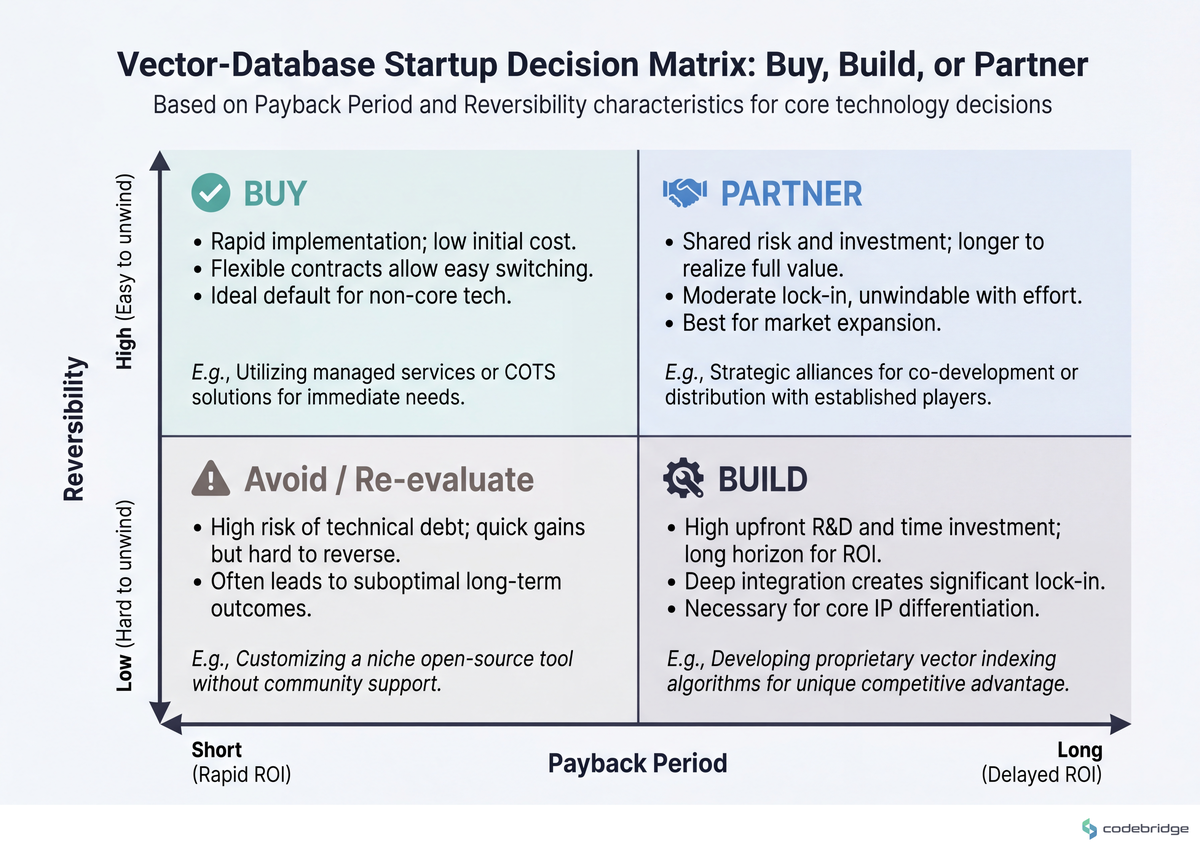
Step 2 — Make buy/build/partner the explicit default for every new system
What to do: Use a four-condition test before any "let's build" decision: (a) it is core to your differentiation, (b) the equivalent vendor cost pays back in under 18 months, (c) compliance forces in-house custody, or (d) a vendor outage materially kills your business. Two or more conditions = build. Fewer = buy or partner.
What good looks like: Your eval harness, your observability stack, your re-ranker baseline, and your data labeling pipeline are vendor-bought or open-source-adopted. Your hybrid index, your tenant isolation, and your write-path replication are built.
Common failure mode: "It's two weeks of work" — and six months later, two engineers are still on it. The decision matrix below is the trade-off most founder-CTOs make implicitly and regret explicitly:
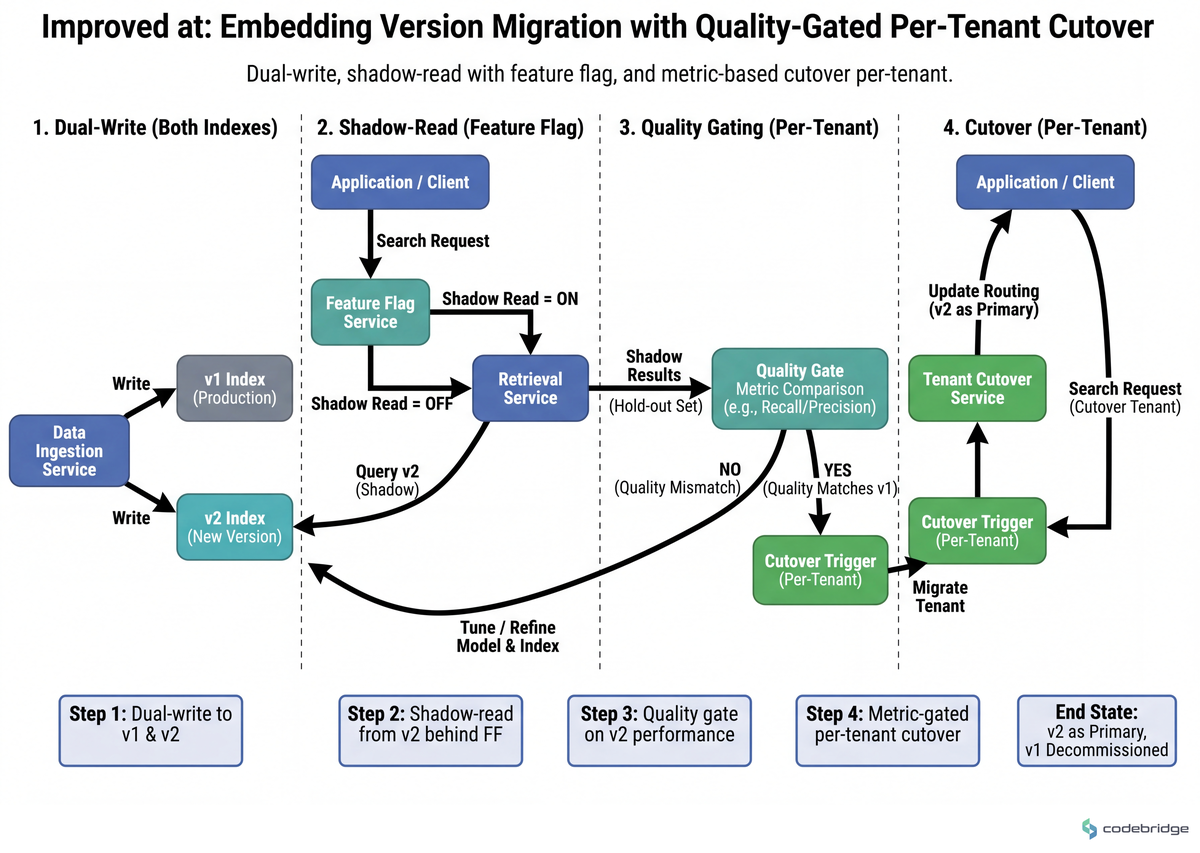
Step 3 — Treat embedding versioning as a database migration, not a refresh
What to do: Adopt the dual-write, parallel-index pattern for embedding model upgrades. Index v2 in parallel with v1, dual-write all new vectors, gate reads with a feature flag per tenant, and cut over only when retrieval quality metrics on a hold-out set match or beat v1.
What good looks like: You can roll an embedding model upgrade full across customers in under two weeks with zero downtime and a documented rollback. The pattern is now standard practice at Pinecone and Supabase (pgvector) precisely because it removes the upgrade cliff.
Common failure mode: Coupling embedding generation directly to user-facing request paths at scale. As the NeuralStackMS guide puts it bluntly:
"Never couple embedding generation directly to user-facing request paths at scale. Use backpressure mechanisms, idempotent writes, dead-letter queues."
NeuralStackMS, Vector Database Architecture & Scaling Guide (2026)
The flow below shows the safe shape of the upgrade — note that v1 is never decommissioned until the metric gate is passed:
Step 4 — Hire a complementary engineering leader before the PR queue explodes
What to do: If you can name three pull requests sitting in your review queue right now that are older than 72 hours, you are already past the threshold. Open the VP of Engineering or Director of Engineering req this month. Look for the inverse of your strengths: where you index on architectural depth, prioritize people-management, delivery discipline, and process design.
What good looks like: Within 90 days of the hire, you personally review fewer than 20% of PRs, attend fewer than half of standups, and your calendar has at least two uninterrupted half-days per week for Horizon 2 work.
Common failure mode: Hiring another version of yourself because the cultural fit is easier. Matt Watson's piece is unambiguous: founding CTOs typically excel at strategic vision and deep technical leadership, and struggle with people management. Hire for the gap, not the comfort.
Step 5 — Buffer hiring time and use hybrid embedded teams for specialist roles
What to do: Assume time-to-hire for senior AI infrastructure engineers will run 60-120 days against your roadmap, not 30. For any roadmap-critical milestone that depends on a hire that hasn't started yet, budget an explicit buffer — and pre-arrange a hybrid embedded team (solution architects plus AI-augmented engineers) you can stand up inside 30 days as a parallel path.
What good looks like: No roadmap commitment to a customer or board slide is gated on a req that hasn't been opened yet. According to Forbes Tech Council's January 2026 prediction set, the manufacturing GenAI launch they profile met its launch window precisely because it combined internal upskilling with embedded hybrid teams from an AI development partner.
Common failure mode: Telling the board the milestone will ship in Q3 on the assumption you'll hire the lead in May, then hiring the lead in August. The board doesn't care which step slipped; they remember the date.
If steps 4 and 5 are both at risk, prioritize 4. A complementary engineering leader unblocks every other step in this playbook; specialist hires unblock one capability at a time.
Close: this week, not next quarter
The founder-CTO Matt Watson described at the top of this article — brilliant at architecture, behind on every timeline — does not need a better roadmap framework. They need to take three specific actions, on three specific days, this week.
Tomorrow morning, open a blank document and write down what percent of your engineering capacity went to Horizon 1, 2, and 3 over the last two sprints. Not what you wish — what actually happened. If H1 is over 80%, you have already found the problem.
Wednesday, list every system your team has built in the last six months that has a vendor equivalent under $500/month. For each one, write a single sentence answering the four-condition test in Step 2. The ones with zero or one condition satisfied are your next deprecation candidates.
By Friday, schedule the conversation you have been postponing — either the VP of Engineering recruiter intro, or the existing hire's expanded scope discussion. If your calendar for next week doesn't contain that meeting, you have just defaulted into another quarter of being the bottleneck.
Not sure where the bottleneck actually is in your roadmap?
Talk to our team about a 60-minute roadmap audit for vector database and AI infrastructure startups.
Diagnostic checklist: where is your roadmap leaking?
Run these against your own system. Score one point per "yes". 0-2 yes: healthy. 3-4 yes: early warning — book step 1 this week. 5+ yes: structural rebuild needed; start with step 4.
Of the last 10 PRs merged on your most critical service, did you personally review more than 6? Yes / No
If asked today, can you state your team's capacity allocation across Horizons 1/2/3 to within ±10% without checking? No = yes
Are two or more of your internally built systems (eval, observability, labeling, re-ranking, pipeline orchestration) duplicating a vendor product available for under $500/month? Yes / No
Would your last embedding model upgrade require either a maintenance window or a re-index that takes more than 24 hours per tenant? Yes / No
Is any roadmap milestone in the next two quarters gated on a specialist hire whose req is not yet open? Yes / No
In the last sprint, did at least one PR sit waiting for your review for more than 72 hours? Yes / No
Can you name, by role, the on-call owner for every stage between embedding generation and end-user query response in your production stack? No = yes
REFERENCES












Heading 1
Heading 2
Heading 3
Heading 4
Heading 5
Heading 6
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Block quote
Ordered list
- Item 1
- Item 2
- Item 3
Unordered list
- Item A
- Item B
- Item C
Bold text
Emphasis
Superscript
Subscript








