



Modular monolith with bounded contexts, or distributed services from day one — that's the fork in front of every fintech founder who says the words "super-app." Pick wrong and you'll spend the next twelve months paying for the architecture instead of building the product. This article gives you the criteria to pick.
The 200ms page that fired 400 queries
A fintech engineering team posted on Hacker News last quarter about a transactional backend that started crawling the moment real user traffic arrived. The schema was fine. Their actual problem was that a single dashboard render was fanning out into hundreds of database round-trips — ORM lazy loads, repeated lookups across feature surfaces, per-widget queries that were independently cheap and collectively fatal.
"The schema wasn't really a problem, but the sheer amount of queries per request." A second commenter on the same thread piled on: "RDS also runs into performance issues the moment you actually have some traffic. A baremetal server is orders of magnitude more capable."
HN commenters, news.ycombinator.com thread on fintech backend scaling
If you've ever owned a multi-feature dashboard, you know this pain in your hands. The thread doesn't tell us how that team resolved it — the discussion fragments before any post-mortem lands. But the failure mode is exactly the failure mode that ends a super-app pitch before you get to the interesting features. Multi-feature surfaces multiply queries. Multiplied queries flatten your read path. A flattened read path makes every product decision feel like an infrastructure tax.
KEY TAKEAWAYS
Query fan-out, not schema, is the scaling killer — a single super-app page load can fire hundreds of round-trips before the database notices anything is wrong.
Premature distribution is the most expensive form of premature optimization — splitting a stable monolith into 47 services without scale pressure trades known debugging cost for unknown distributed-systems cost.
Fintech bounded contexts are not equal — payments, KYC, and ledger have different scaling curves, latency budgets, and compliance isolation needs. They are the natural extraction seams.
Willingness-to-pay in fintech concentrates around portfolio analytics and risk tooling, not lifestyle widgets — feature roadmaps that ignore this lose to focused competitors before scale ever matters.
The Hidden Problem: architectural obesity arrives before scale does
The instinct, when query fan-out hits, is to declare "we should have split this into services." That instinct is what Martin Fowler has spent a decade warning against. His MonolithFirst essay remains the cleanest statement of the trade-off: you cannot draw correct service boundaries before you understand the workload, and the cost of redrawing them after distribution is far higher than the cost of refactoring within a monolith.
The fintech super-app is the most seductive context for getting this wrong. You're already thinking in features — payments, cards, FX, savings, investments, crypto, BNPL, KYC, lending — so it feels obvious that each one should be its own service. It isn't. It feels obvious because the org chart looks like microservices. The org chart is not a system design.
The decision below is the one that actually matters. The diagram below contrasts the two paths across the four pressures that fintech super-apps actually feel.
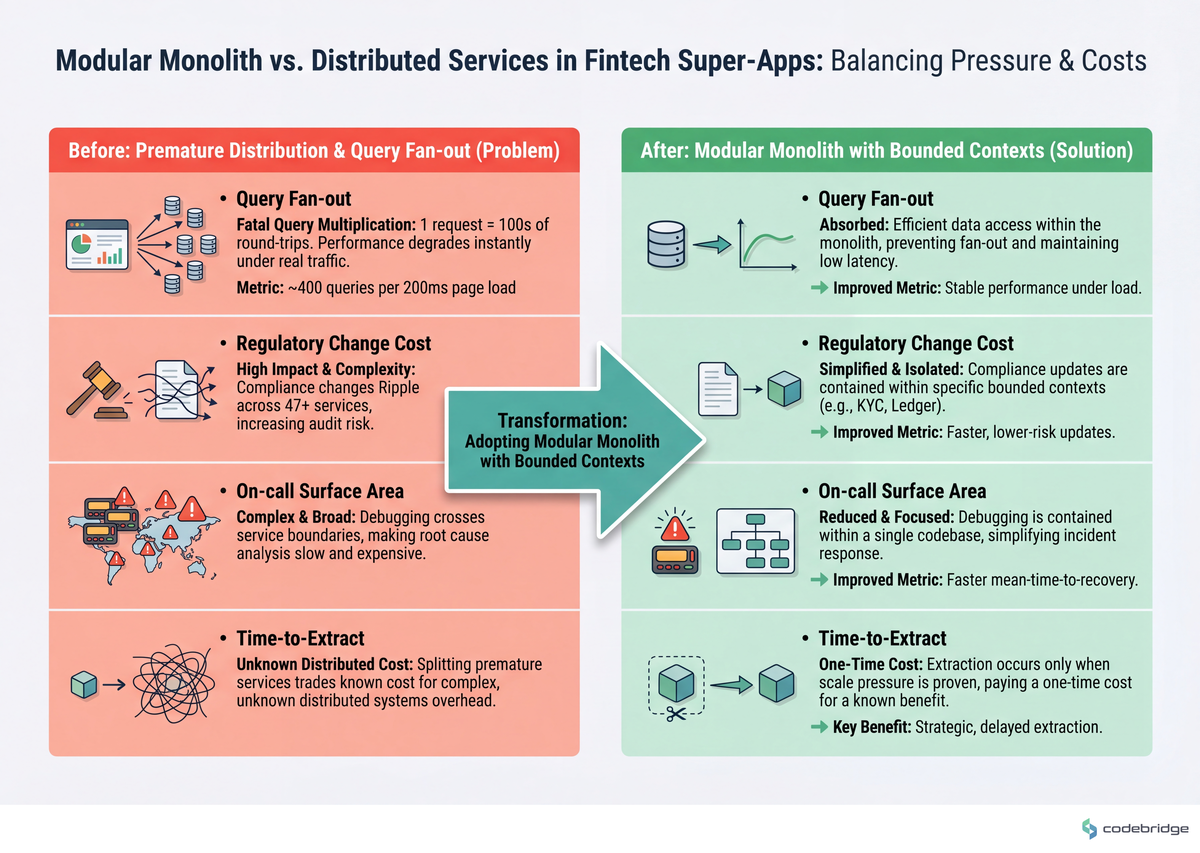
Real stories from the field
On r/softwarearchitecture, a developer described a stable Python monolith — roughly 200K lines of code, eight years old, handling 50K requests per day with a low crash rate. Their lead architect proposed splitting it into 47 microservices.
"Not perfect, but it handles 50K req/day fine. Rarely crashes. Easy to debug."
r/softwarearchitecture poster, Reddit thread
The thread is a lesson in the difference between "could scale" and "needs to scale." A senior commenter on the same HN scaling discussion put it more bluntly: "Almost every system I work on is architecturally obese and while it 'could scale' it has never and will realistically never need to." Architectural obesity is the real cost of distributing too early — every feature now requires cross-service coordination, every deploy touches multiple repos, every on-call rotation owns more surface than any one person can hold in their head.
And on the demand side, a Reddit analysis of 9,300+ "I wish there was an app" posts found that finance was the single largest pay-signal category, with 193 explicit signals. Users were asking for portfolio analytics and risk tooling — and explicitly looking for "premium" versions that handle their data securely.
"Users are asking for specialized portfolio trackers and risk analysis tools and are explicitly looking for 'premium' versions that handle their data securely."
r/SaaS analysis post, Reddit thread
This is your willingness-to-pay signal, and it cuts directly against the "more lifestyle widgets" instinct. The teams that outpace Revolut do so by going deeper on the few features where users will actually pay a premium, not by adding the eleventh feature surface that nobody asked for. Architecture should follow that focus, not pre-empt it.
The Pattern: bounded contexts you'd extract anyway
The teams we see win this fork have one thing in common — they pick a default architecture and a small, explicit set of conditions under which they break that default. The default is a modular monolith. The exceptions are narrow. Everything else stays inside.
Three bounded contexts almost always justify their own service in fintech: ledger (because the consistency and audit boundary is non-negotiable), KYC/identity (because the compliance isolation and PII blast radius are different from your product surface), and payments execution (because the latency budget and third-party processor integration is different from a CRUD path). Almost everything else — accounts, cards, transactions display, savings, FX rates, notifications, user preferences — lives happily as modules inside the same deployable.
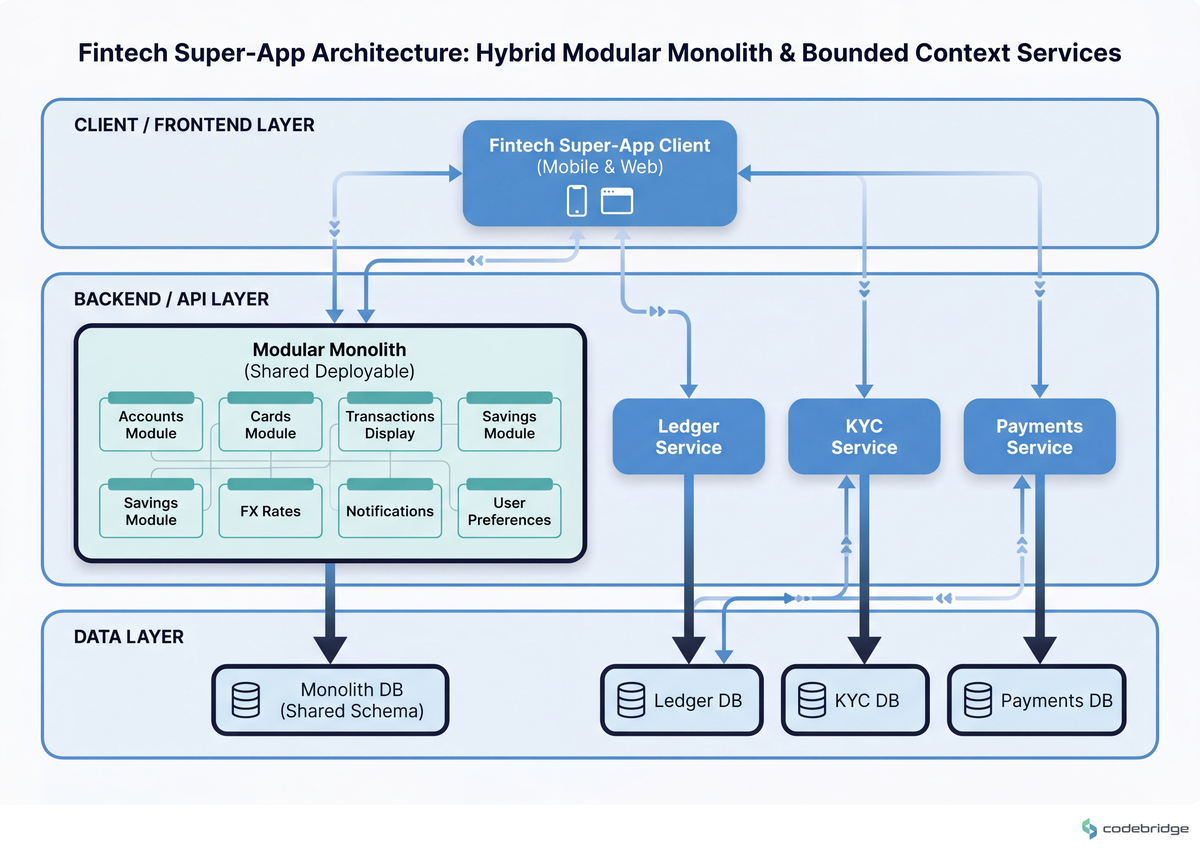
The Framework: when to keep modules in, when to cut them out
Each item below has a measurable trigger. If the trigger isn't met, the default — keep it inside the monolith — wins.
1. Extract a service only when one of three triggers fires
The triggers are: (a) the module's scaling curve has diverged sharply from the rest of the app (your ledger writes are growing 10x faster than your dashboard reads), (b) a regulatory boundary requires deploy isolation (a regulator wants attestable evidence that your KYC store is not co-deployed with marketing analytics), or (c) the module's failure mode is unacceptable to couple with the rest (a payment-execution outage taking down account view is a worse outage than two separate ones). If none of these three are true today, the right answer is "module, not service."
2. Read models per feature surface, not per entity
The HN fan-out story is the canonical example of this failure. Build the read path around the surface that the user actually sees — one query, one cached projection, one denormalized view per dashboard tile — instead of round-tripping the entity graph on every render. A concrete pattern: each dashboard widget owns a materialized read model with a 30-60 second staleness budget, refreshed asynchronously, and the widget renders from that projection alone. Dashboard latency becomes a function of cache hit rate, not entity count.
3. Benchmark managed databases against bare-metal before you commit
The HN commenter who said "RDS runs into performance issues the moment you actually have some traffic" was being provocative, but the benchmark is cheap to run and the answer matters for your unit economics. Run your top three transactional workloads on RDS at expected peak, and on a bare-metal Postgres at the same hardware tier. If the gap is more than 3x at p95, your scaling story has a managed-cloud tax baked in that you should know about before you commit your roadmap to it.
4. Pipeline budget: every minute over six is debt
Your CI/CD time is a leading indicator of architectural drift. If a deploy of a single feature touches three repos and takes 40 minutes, you've already paid for the network boundaries — you just haven't seen the bill yet. The threshold we use: any feature deploy that takes more than six minutes full is debt that compounds. Track it weekly. The week it crosses fifteen minutes is the week you stop adding services.
5. Feature prioritization follows willingness-to-pay, not feature-parity
The 9,300-post Reddit analysis found that "premium portfolio analytics with strong data-security signaling" was the highest pay-signal in finance. That's a roadmap input, not a UI input. To outpace Revolut, you don't ship the eleventh feature surface; you ship the second feature surface twice as deep. Architecture-wise, this means your ledger and analytics paths get the engineering hours, and your "lifestyle widget" surfaces get whatever time is left.
The Verdict
Back to the HN team that started this article — the dashboard fan-out crew. We don't know how their thread ended, and that's the honest answer. What we do know is what comes next for a founder facing the same fork.
Pick the modular monolith if your annual transaction volume is under ~$50M, you're operating in one or two regulatory regimes, your team is under thirty engineers, and you haven't yet demonstrated that any single feature surface has a divergent scaling curve. This is the default for technology founders building super-apps. It will be the right call eight times out of ten.
Pick the distributed split only when you can name the specific bounded context — ledger, KYC, or payments execution — that has a measurable scaling, compliance, or failure-isolation reason to live alone, AND you can describe the latency or throughput threshold that justified extracting it. "We might need to scale" is not a threshold.
Pick neither yet if you're still finding product-market fit. Premature architecture is just premature optimization wearing a tie.
Your concrete next step, before your next architecture meeting: open the slowest endpoint in your dashboard, turn on query logging, and count the round-trips for one realistic user session. If the number is over 50, you have your first project. That count takes thirty minutes. Every architectural conversation you have without it is theoretical.
Stuck on which contexts to extract first?
Talk to our team about auditing your fintech architecture for over- and under-distribution.
Diagnostic Checklist: is your super-app architecture fighting you?
Run these against your current system. Score one point per Yes. 0-2 = healthy; 3-4 = drift, audit within the quarter; 5+ = rebuild candidate.
Does a single authenticated dashboard load fan out into more than 50 database queries when traced full? Yes / No
Has a single feature deploy in the last month required coordinated releases across three or more repositories? Yes / No
Is there a service in your stack that you split before it had a documented scaling, compliance, or failure-isolation trigger? Yes / No
Does your full CI/CD pipeline (commit to production) take longer than fifteen minutes for a typical change? Yes / No
Are your ledger writes co-deployed with non-financial code paths (notifications, marketing analytics, user preferences)? Yes / No
If a regulator asked you tomorrow to attest that PII storage is isolated from product analytics, would you need a code change to prove it? Yes / No
In the last quarter, did the architecture (not the team, not the product spec) become the bottleneck on a feature ship date? Yes / No













Heading 1
Heading 2
Heading 3
Heading 4
Heading 5
Heading 6
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Block quote
Ordered list
- Item 1
- Item 2
- Item 3
Unordered list
- Item A
- Item B
- Item C
Bold text
Emphasis
Superscript
Subscript









