



Last quarter, a network engineer at one of the teams we work with handed in their resignation. The trigger wasn't compensation, wasn't burnout in the usual sense — it was the firewall stack. As one Redditor in r/networking put it about a similar situation:
"One of our engineers recently resigned due to all bugs and problems with Cisco FTD and FMC," he wrote. "He couldn't stand it anymore."
u/anonymous, Reddit r/networking
If you're a Field-CTO standing up an HPE networking and AI ecosystem in 2026, that thread should land hard. Partner choices don't just show up in your TCO model — they show up in your retention dashboard. And when the partner stack is a moving target of agentic AI controllers, 400/800G Ethernet fabrics, RoCEv2 congestion knobs, and Model Context Protocol bridges to legacy gear, the wrong alignment doesn't just slow training jobs. It walks out the door with your senior engineers.
The Hidden Problem: Networking Is Now the AI Bottleneck
The dominant industry story about AI infrastructure is still "buy more GPUs." That story is two years out of date. A peer-reviewed ACM study on cloud-scale deep learning training found that more than 40% of practitioners cite I/O and networking as primary bottlenecks to scaling AI training — not GPU availability. Move the same workload from legacy 25/40G Ethernet onto a modern 200/400G fabric with congestion control, and benchmarking studies show 30–40% reductions in job completion time with identical compute.
Meanwhile, the data center itself is the second hidden problem. Uptime Institute's Global Data Center Survey 2024 found that only ~40% of enterprise facilities can support AI-grade power density without significant upgrades, and AI servers draw 3-5× more power per rack than traditional servers. The networking decisions — leaf-spine vs AI pod, copper vs optics, RoCEv2 tuning — now live inside the same architectural conversation as liquid cooling and busbar capacity. Field-CTOs who treat the fabric as a separate workstream lose the project at the rack.
KEY TAKEAWAYS
Networking has overtaken GPUs as the dominant AI scaling constraint in enterprise deployments, with 30-40% training-time reductions available from fabric upgrades alone.
Hybrid is the steady-state for enterprise AI: 61% of enterprises running AI at scale use a hybrid on-prem + cloud mix (Forrester), not a single-environment strategy.
Ethernet/RoCEv2 is winning the enterprise fabric layer, with high-speed Ethernet projected to capture ~20% of data center switch revenue from AI workloads alone by 2027 (IDC).
Partner stack instability has measurable talent-retention costs — engineers leave when the operational ergonomics of vendor platforms degrade faster than the feature set improves.
Agentic AI for NetOps is moving from research to production, requiring governance frameworks before the first autonomous remediation runs.
Patterns We're Seeing in the Field
The clearest signal we see across enterprise AI rollouts in 2026 isn't a vendor preference — it's whether the Field-CTO has aligned partners on three architectural primitives early, or is renegotiating them mid-build.
Ericsson's public work on agentic AI for network operations is the cleanest case study in the open right now. In their BriefingsDirect discussion on modern data architecture, Ericsson describes harmonizing global network telemetry through open table formats (Apache Iceberg) and using agentic AI models that interact with each other to refine recommendations before changes are applied to live networks. That's the operational target state — a unified data plane that engineering partners plug into, rather than each vendor shipping a sealed monitoring silo. Field-CTOs aligning with HPE's networking and AI ecosystem should read Ericsson's choice of an open table format as a forward indicator: by 2026, fragmented telemetry is a deal-breaker, not a tolerable seam.
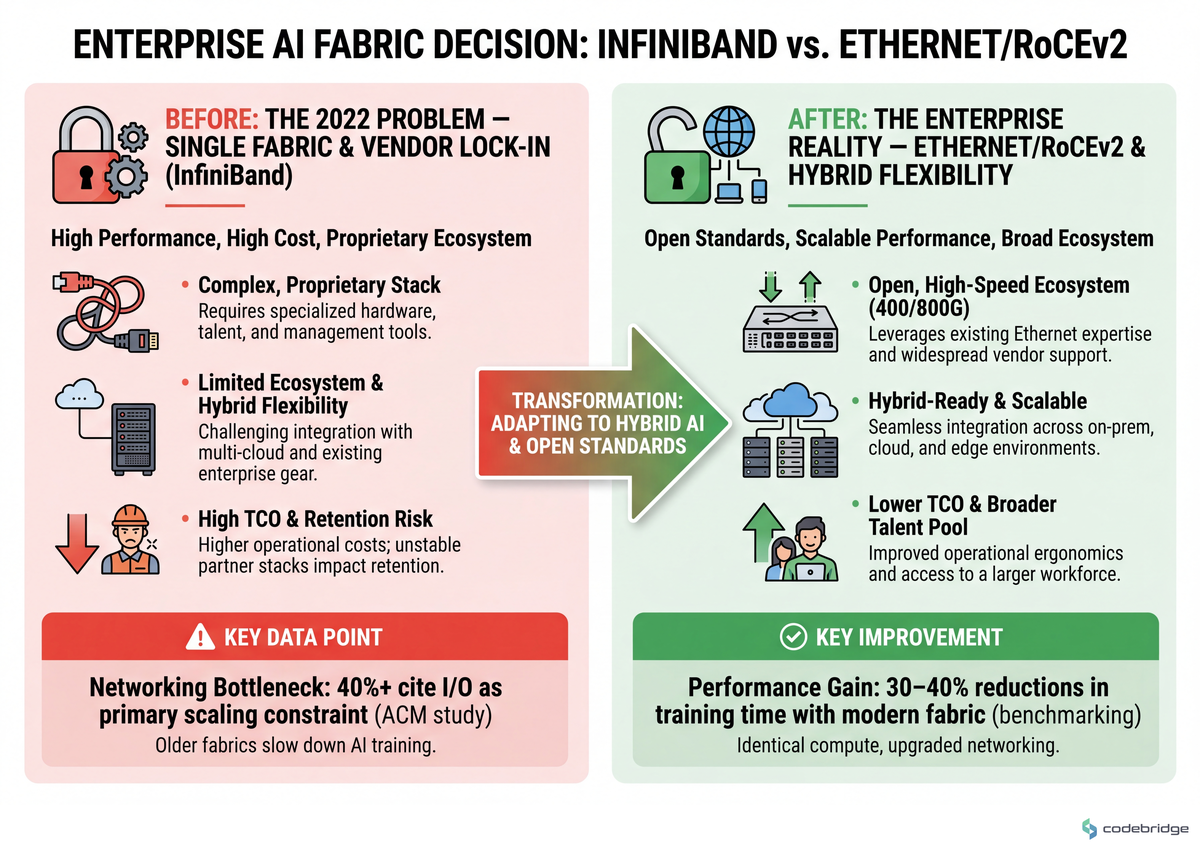
The fabric question is where partner alignment most often breaks down. A dev.to architecture writeup, "InfiniBand Is Losing the Fabric War," framed it bluntly:
"The tightly coupled NVIDIA InfiniBand stack delivers real performance and real lock-in."
NTC Tech, dev.to
That tension — performance vs heterogeneity — is exactly why the Ultra Ethernet Consortium (HPE, AMD, Broadcom, Cisco, Intel, Meta, Microsoft) exists. IDC forecasts that Ethernet captured roughly 33% of AI cluster ports by 2023, with share growing as 400/800G Ethernet matures. If your partner ecosystem assumes a single fabric forever, you're solving the 2022 problem.
The comparison below shows the trade-offs you'll actually negotiate with partners:
The third axis is the one most partner conversations skip: integrating AI into existing infrastructure that was never designed for it. An instatunnel dev.to writeup on Model Context Protocol bridges to legacy hardware described a failure mode we keep seeing:
"A centralised review bottleneck was slowing production adoption." The team had governance — they just hadn't delegated it, so every MCP-mediated change queued behind a single review board while global data center electricity demand climbed from 415 TWh in 2024 toward a projected 800 TWh by 2026.
instatunnel team, dev.to
Governance bottlenecks are how strong architecture choices die in execution. The partners who succeed in HPE's ecosystem in 2026 are the ones who arrive with delegated approval models, SSO-backed audit trails, and energy budgets attached to architecture proposals — not just a SKU sheet.
The Pattern: What the Aligned Teams Actually Do
The thesis of this playbook: alignment is a procurement-time problem, not a deployment-time problem. By the time partners are arguing about RoCEv2 ECN thresholds or Iceberg schema evolution in week 14, the budget conversation is already lost. The steps below are what we use to front-load those decisions.
The Playbook: Six Steps to Align Engineering Partners With HPE's Networking and AI Ecosystem
This is a sequential procedure. Do not parallelize steps 1 and 2 — the fabric decision constrains every downstream partner conversation. The process flow below illustrates the dependency order:
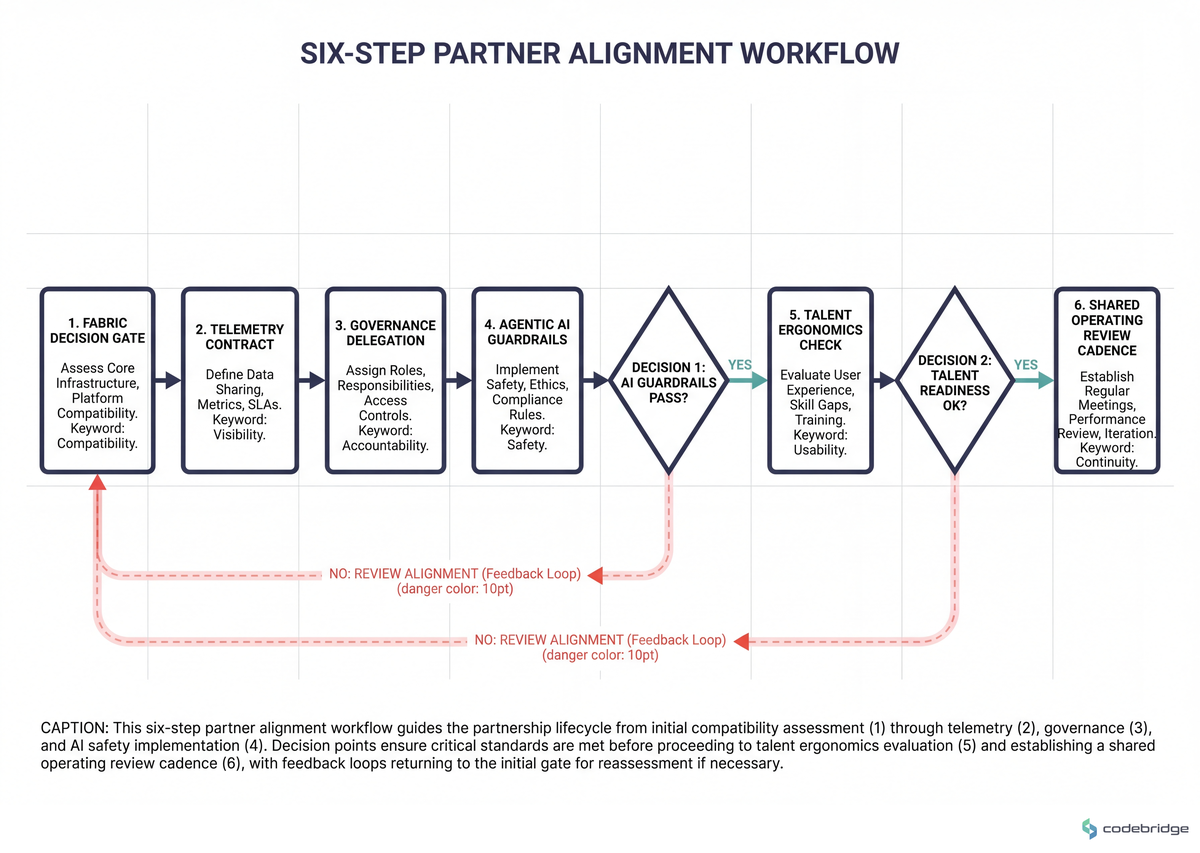
Step 1 — Lock the fabric decision before partner selection
What to do: Classify every planned AI workload into three buckets — homogeneous-NVIDIA training, heterogeneous-GPU training, and inference-only — and assign a fabric per bucket. Default rule: if heterogeneous GPU or hybrid cloud is on the 24-month roadmap, anchor on 400/800G Ethernet with RoCEv2. If the workload is exclusively large-model training on a single-vendor GPU island and lock-in is acceptable, InfiniBand still wins on raw latency.
What good looks like: A one-page fabric decision memo that names the workload class, the chosen fabric, and the trigger condition for revisiting (e.g., "revisit if >30% of training capacity is non-NVIDIA by Q3").
Common failure mode: Letting the GPU vendor pick the fabric for you. The InfiniBand-stack lock-in is real and documented; partners aligned with HPE's Ultra Ethernet direction will quietly route around it if you don't make the call explicitly.
Step 2 — Standardize telemetry on an open table format before the first deploy
What to do: Require every networking and AI partner to land telemetry in a single open table format (Apache Iceberg is the current default — Ericsson's choice, and the one HPE's data fabric tooling integrates against most cleanly). Reject any partner monitoring stack that requires a sealed SaaS dashboard as the system of record.
What good looks like: A schema registry shared across partners, with lineage tags for every network KPI feeding the AI ops model.
Common failure mode: Accepting "we can export to your warehouse" as equivalent to "we write to your shared table." Export pipelines rot. Schemas drift. By month six, your AI ops model is training on stale data and no one notices until a P1.
Step 3 — Delegate governance before the first agentic AI controller goes live
What to do: Write the governance delegation matrix during the partner contract phase. For each class of agentic action (read-only diagnostic, recommendation-only, autonomous remediation), name the approval tier and the reviewable artifact. SSO-backed audit trails, tagged AI-assisted commits, and a tiered rollout (read-only copilots first, autonomous actions last) are table stakes — not optional.
What good looks like: Mean time from agentic recommendation to applied change drops below 48 hours for low-risk classes; high-risk classes still gate on human review, but the gate is delegated to a named role, not a committee.
Common failure mode: The centralized review bottleneck the dev.to MCP writeup described — every change queued behind one board, throughput collapses, and the agentic AI capability becomes shelfware.
Step 4 — Attach an energy and density budget to every architecture proposal
What to do: Require partners to submit a kW-per-rack figure, a cooling delta, and an annual TWh projection for every cluster design. Reject proposals that don't model the elevated AI-vs-traditional power uplift. If your facility is in the ~60% of enterprise data centers that can't support AI density today, the upgrade plan is part of the partner deliverable, not a follow-on project.
What good looks like: The architecture review and the facilities review happen in the same meeting, with the same numbers on the slide.
Common failure mode: Treating power and cooling as a facilities problem. By the time the rack ships and won't fit, you've burned the integration window.
Step 5 — Run an operational ergonomics check on every shortlisted partner stack
What to do: Before signing, send two senior engineers to spend a week in the partner's management plane — the firewall console, the fabric controller, the AIOps UI. Ask them whether they'd quit over it. We're not joking. The Cisco FTD/FMC thread above is one data point; we hear variants of it on every diligence call. If your senior engineers wouldn't touch the stack voluntarily, neither will the engineers you're trying to hire in 2026.
What good looks like: A written ergonomics review with three concrete pain points and a vendor-acknowledged remediation timeline.
Common failure mode: Buying the feature matrix instead of the workflow. Feature parity is necessary; operational maturity is what keeps the team.
Step 6 — Codify the shared operating review cadence
What to do: Lock a monthly joint review with each Tier-1 partner, on a fixed agenda: telemetry schema drift, agentic AI action log, fabric utilization vs forecast, and one operational pain point chosen by the partner's on-call lead. Cancel the review only by mutual agreement.
What good looks like: By month four, partners arrive with their own data pulled from your shared Iceberg tables, not slideware.
Common failure mode: Quarterly business reviews replacing operational reviews. QBRs are commercial. Operational reviews are technical. Don't merge them.
From Playbook to Calendar
The Cisco FTD/FMC thread that opened this article doesn't tell us how the team replaced the stack — the last posts are the engineers still venting. Your job as a Field-CTO is to make sure your own thread never gets written. So here's the 30-minute artifact: tomorrow morning, draft the one-page fabric decision memo from Step 1 — workload class, chosen fabric, revisit trigger. Wednesday, send your top three partner candidates a written request for their telemetry schema and their governance delegation matrix; whoever can't produce both within five business days is dropped from the shortlist. By Friday, book the Step 5 ergonomics week with the two finalists. That sequence — fabric, telemetry, ergonomics — is the smallest possible loop that surfaces the misalignments before they cost you nine months of schedule and a senior engineer.
Building or rebuilding your AI infrastructure partner stack?
Talk to our team about running a Step 1-6 alignment audit on your current ecosystem.
Diagnostic Checklist: Is Your Partner Ecosystem Actually Aligned?
Run these seven questions against your current state. 0-2 "Yes" answers: healthy alignment. 3-4: at risk, schedule a partner review this quarter. 5+: you are paying alignment debt every sprint — escalate to a full Step 1-6 reset.
Did your last AI fabric decision get made by the GPU vendor's reference architecture rather than by an explicit workload-class memo? Yes / No
Do two or more of your partners write network telemetry into separate, vendor-owned databases that don't share a schema registry? Yes / No
Does a single review board approve every agentic AI action class, regardless of risk tier? Yes / No
Was the last architecture review you ran missing a kW-per-rack figure on the deck? Yes / No
Has a senior engineer on your team mentioned a partner management UI as a reason they're considering leaving in the past six months? Yes / No
Do your partner reviews happen quarterly with a commercial agenda rather than monthly with an operational one? Yes / No
If a new compliance requirement landed tomorrow, would integrating it require a code release from your fabric vendor rather than a config change in your shared data plane? Yes / No
REFERENCES













Heading 1
Heading 2
Heading 3
Heading 4
Heading 5
Heading 6
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Block quote
Ordered list
- Item 1
- Item 2
- Item 3
Unordered list
- Item A
- Item B
- Item C
Bold text
Emphasis
Superscript
Subscript








