





Thesis: a new CTO's first strategic initiative should be chosen to maximize decision velocity, not visible re-architecture. Pick the constraint whose removal unblocks the most parallel work — and prove it in 90 days.
The Friday-Night Slack
Imagine a senior engineer at a mid-size outsourcing firm getting a Friday-evening Slack from a client CTO they staffed last quarter. The message reads: "Three weeks in. The board wants my 90-day plan by Monday. I have a list. None of it feels strategic. Help."
You open the doc. It's the predictable list of any new technical leader — re-platform off the legacy monolith, hire two staff engineers, stand up a platform team, finally write down the deploy process. Each item would consume two quarters. None of them, alone, would change how the company operates. If you're a senior engineer being elevated into a CTO seat at a portfolio company, or the technical lead the new CTO leans on during the first 90 days, this paralysis will land on you. The "list of good ideas" is the trap.
KEY TAKEAWAYS
Most first initiatives are chosen for visibility, not use. Re-architectures look strategic; constraint removal compounds.
Decision velocity is a measurable input. Time-from-decision-raised to decision-shipped is the lead indicator the board can't read on its own.
A defensible 90-day initiative names three things up front: the constraint, the baseline metric, and the proof point at week four.
Reversibility is part of the choice. A first move you can roll back in a sprint is worth more than a "perfect" move you can't.
The Hidden Problem: New CTOs Optimize the Wrong Layer
The dominant story new technical leaders tell themselves goes: "The codebase is messy, so the initiative is re-architecture." The board hears this and nods, because re-architecture sounds strategic. Six months in, the platform is mid-rebuild, the original list still has 11 untouched items, and the CEO is asking why product velocity has not moved.
The systemic issue here is well-documented in operator literature. The DORA program's research into elite versus low-performing engineering organizations consistently finds that the difference is not the technology stack — it's the rate at which decisions translate into deployed change. The four key metrics (deployment frequency, lead time for changes, change failure rate, mean time to recover) all measure the same underlying thing: how fast does an idea travel from "raised" to "running in production"? You can read the framework at dora.dev.
If you choose a re-architecture as your first move, you've committed to a multi-quarter project whose value materializes after the period in which the board has decided whether you were a good hire. The diagram below shows why that's the wrong quadrant to enter:
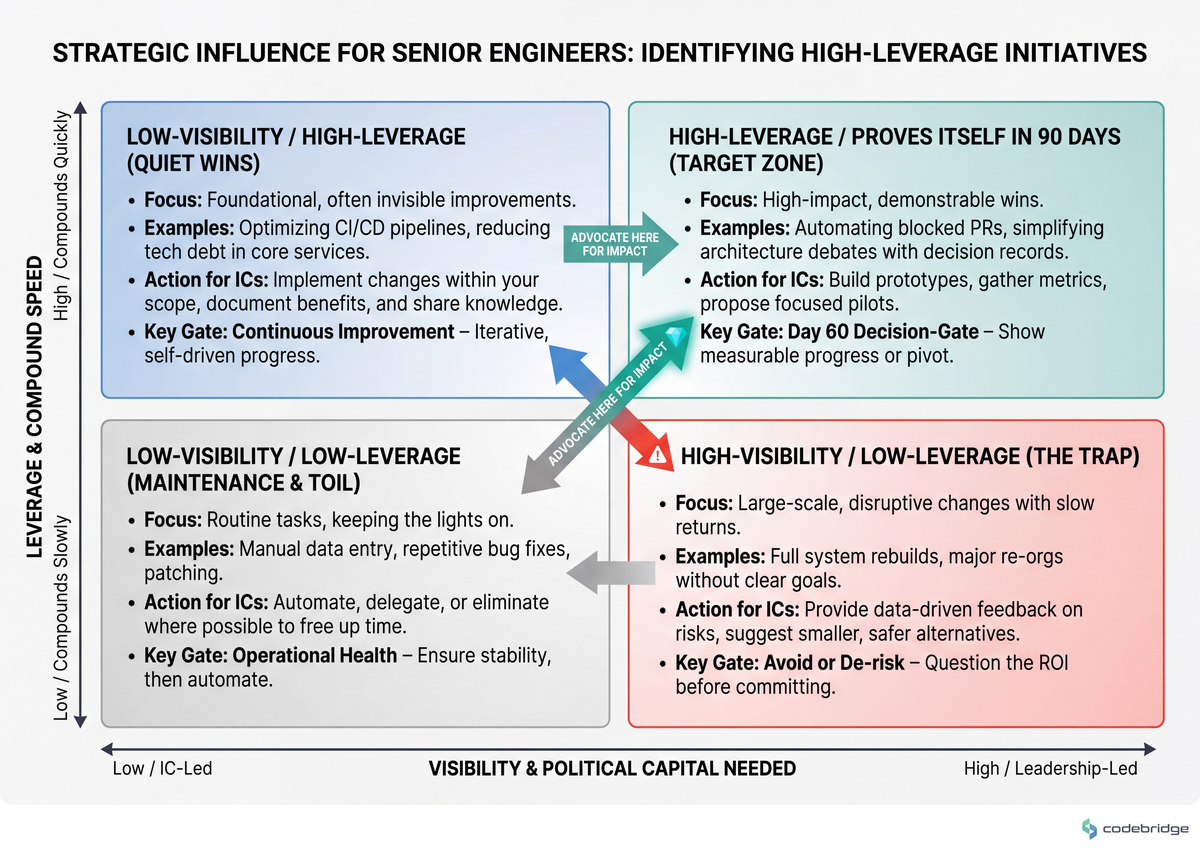
Classic operator wisdom on executive transitions makes the same point from a non-technical angle: the first 90 days establish the operating rhythm the rest of the tenure inherits. Choose a first move that the rest of the org has to respond to, not one they have to wait for.
What "Strategic" Actually Looks Like
Will Larson — author of Staff Engineer and An Elegant Puzzle, formerly CTO at Calm — has written extensively at lethain.com about the difference between engineering strategy and engineering activity. The shorthand: a strategy names a constraint, picks one acceptable trade-off, and tells the rest of the organization what they no longer have to argue about. A list of projects doesn't do that. A list of projects generates arguments.
One of our recent engagements: a ~45-person B2B SaaS company brought us in alongside their newly-promoted CTO, who'd been their Principal Engineer the day before. Stack genre: Python/Postgres monolith with a small services edge, on AWS. Engagement: 6 months, embedded delivery team. The CTO's first instinct was a service extraction. We pushed back and asked her to measure the lead time from "engineer raises a question about a domain boundary" to "decision is documented and unblocks the work." The number came back at 17 business days. Six months later, after she replaced async-Slack-debate with a weekly 30-minute decision-record meeting and a public RFC repo, that number sat at 4 days. The service extraction never happened. It also stopped being necessary.
The Playbook: Seven Steps to a Defensible First Initiative
The following sequence is what we walk new CTOs (and the senior engineers advising them) through during the first six weeks. Each step has a "what good looks like" anchor and a common failure mode. Don't skip the order — step 3 makes no sense without step 1.
Step 1 — Run a Decision-Velocity Audit (Week 1)
What to do: Pick the last 20 non-trivial technical decisions (anything bigger than a library choice). For each, log: date raised, date decided, date shipped. Calculate median raised-to-shipped in business days.
What good looks like: Median under 10 business days for routine calls, under 30 for cross-team calls. If your number is 25+ for routine, you've found your constraint without needing to look further.
Failure mode: Sampling only "the loud ones." Pick decisions across teams, not just the ones that came to you.
The diagram below shows how the audit looks when you map raised-to-decided against decided-to-shipped — most stalls live on one axis, not both:
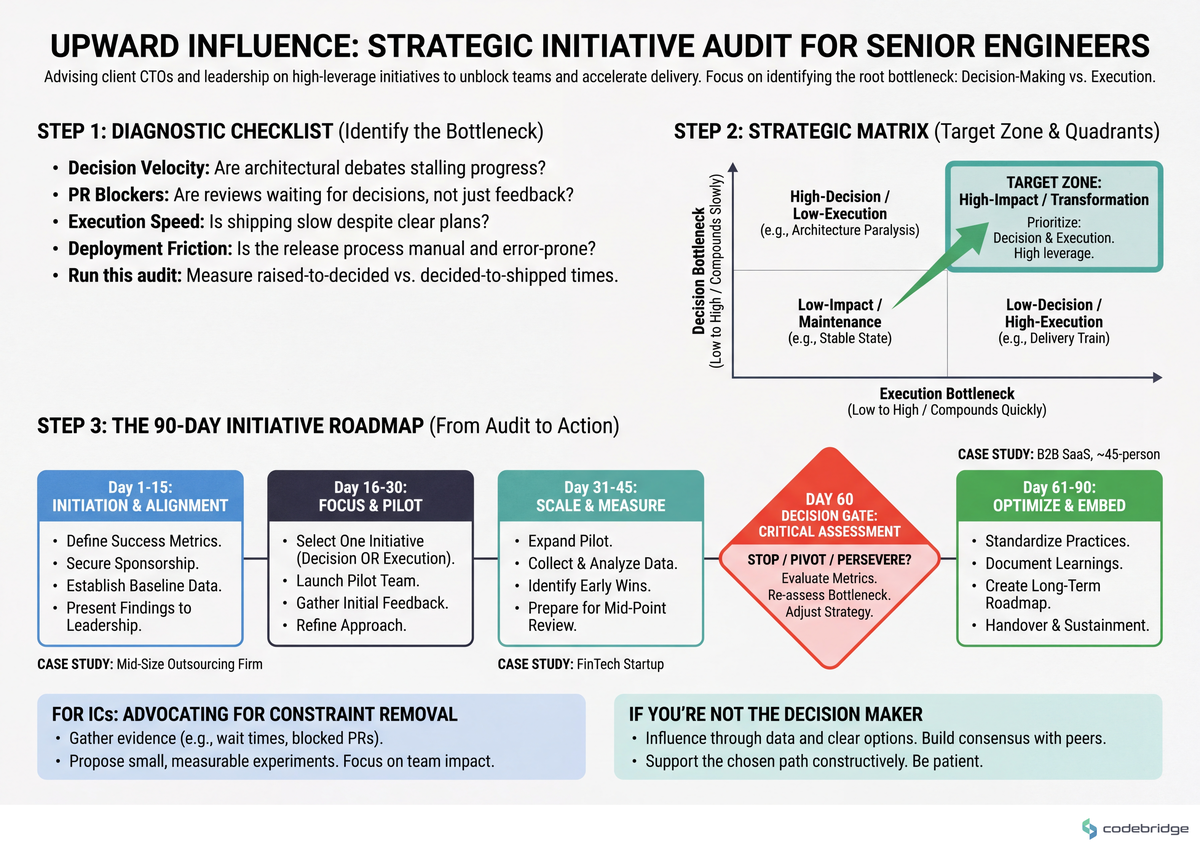
Step 2 — Identify the One Constraint
What to do: From the audit, name the single bottleneck whose removal would compress the most other timelines. Test it: list the next four items on your "good ideas" list and ask, for each, "does this get materially easier once the constraint is gone?" If three of four become easier, you've found it.
What good looks like: A one-sentence statement: "Our constraint is X. Removing it unblocks Y, Z, and W."
Failure mode: Picking the constraint that's most visible to the CEO. The most visible is rarely the most leveraged.
Step 3 — Choose a 90-Day Outcome with 12-Month Compounding
What to do: The initiative must show a measurable outcome in 90 days AND keep paying off after. If you can only show one or the other, you've picked wrong.
What good looks like: "Cut decision lead time from 17 to 7 business days by end of Q2; expect 20% throughput lift across all squads as a downstream effect over the following two quarters."
Failure mode: Choosing an initiative whose first measurable signal lands in month five. By then, the board has already formed an opinion about you.
Step 4 — Pre-Commit to the Baseline Number
What to do: Write down — in a shared doc, dated, before any work starts — the number you'll be judged against. If your initiative is decision velocity, that's the median lead time today. If it's deploy frequency, that's the current weekly count.
What good looks like: The baseline is visible to the CEO and at least one board member before work begins.
Failure mode: Measuring the baseline after starting work. You will, unconsciously, pick the baseline that makes your improvement look bigger.
Step 5 — Build the Three-Sign-Off Coalition
What to do: Get an explicit written yes from (1) the CEO, (2) one senior IC who could credibly veto the technical approach, and (3) someone from finance or ops who controls a downstream resource.
What good looks like: All three sign-offs reference the same one-sentence statement from Step 2. If their summaries diverge, your initiative is not yet defined tightly enough.
Failure mode: Skipping the senior IC. They will find a reason to be the loudest skeptic in month two if they weren't a co-author in week three.
Step 6 — Ship a Thin Slice in Week Four
What to do: Whatever the initiative is, deliver something visible and irreversible by the end of the first month. For a decision-velocity push, that might mean publishing the first three RFCs in a public repo. For a deployment-frequency push, that might mean cutting one team's deploy time by half.
What good looks like: The thin slice is what you reference in the 30-day update. It exists, it's used, and you can name who used it.
Failure mode: Spending week four still in "design phase." The thin slice is not the polished version — it's the proof the initiative is real.
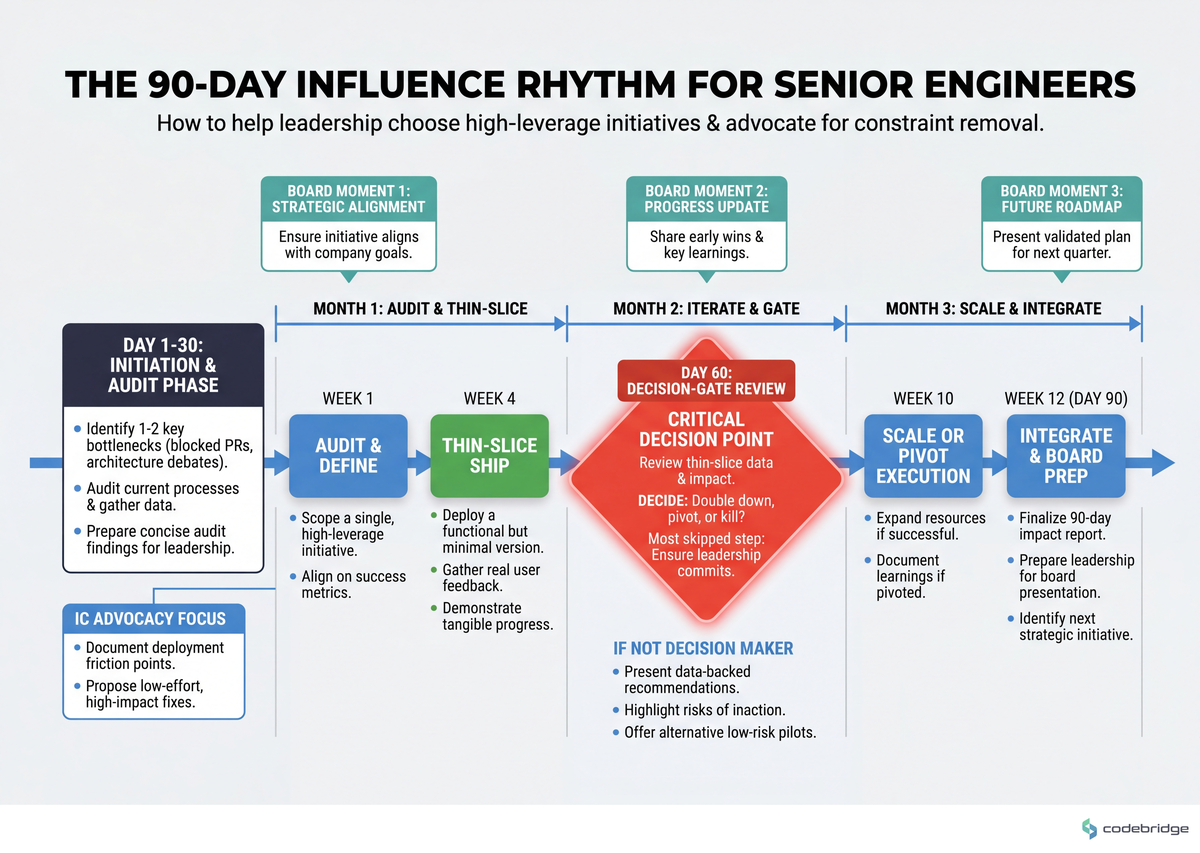
Step 7 — Schedule the 30 / 60 / 90 Written Review
What to do: Three calendar invites, written reviews (not slides), each one comparing current state to the pre-committed baseline. The 60-day review is the moment to shift if the data says you've picked the wrong constraint.
What good looks like: Each review is 2-4 pages, written by you, circulated 24 hours before. The board reads ahead.
Failure mode: Treating the 60-day review as a status update instead of a decision gate. If month two shows the constraint isn't moving, sunk-cost thinking will keep you on a dying initiative.
The timeline below shows where each step lands across the 90 days, and which board moments each one feeds:
One Caveat: Not All Constraints Are Decision Velocity
The framework above assumes the bottleneck is internal coordination. Sometimes it's not. If your audit reveals a healthy 4-day median lead time but shipping is still slow, the constraint is execution capacity, not decision-making — and the first initiative should be hiring or platform investment instead. The point is not that "decision velocity is always the answer." The point is that you measure before you commit, and the measurement tells you which playbook to run.
If you cannot name your first initiative in a single sentence that includes the constraint, the baseline number, and the 90-day proof point, you don't have an initiative yet — you have a list. Don't bring the list to the board.
Close: What to Do Next Week
Back to the Friday-night Slack. The senior engineer's reply isn't a list of recommended initiatives — it's a worksheet. Tomorrow morning, pull the last 20 technical decisions and timestamp them. Wednesday, name the constraint and write the one-sentence initiative statement. By Friday, have the baseline number documented and the three sign-offs scheduled. That's the Monday board deck — not 11 bullet points, but one defensible move with a number attached.
The 30-minute artifact: open a doc titled "First Initiative — [Your Name]" and write three lines. Constraint: ___. Baseline today: ___. Target at day 90: ___. If you can't fill all three lines without making something up, you have your work for next week.
Stepping into a CTO seat — yours or a client's — and want a second set of eyes on the audit?
Talk to our team about a 2-week decision-velocity diagnostic before you commit to a first initiative.
Diagnostic Checklist: Is Your First Initiative Defensible?
Run this against your current draft. Count the yeses.
Can you state your first initiative in a single sentence that names the constraint, the baseline metric, and the 90-day proof point? Yes / No
Does removing your chosen constraint demonstrably unblock at least three other items on the "list of good ideas"? Yes / No
Is the baseline number written down, dated, and shared with at least one stakeholder outside engineering — before any work starts? Yes / No
Has a senior IC who could credibly veto the technical approach signed off in writing? Yes / No
Does the CEO know the exact week they'll see the first proof slice — and what "proof" specifically means? Yes / No
If month two reveals you picked the wrong constraint, can you reverse course in a single sprint without a multi-month rip? Yes / No
Are the 30-day, 60-day, and 90-day written reviews already on the board's calendar? Yes / No
Scoring: 6-7 yes = defensible, run it. 4-5 yes = the initiative has the right shape but the coalition or measurement is soft; fix before Monday. 0-3 yes = you're still in the "list of things" phase. Don't bring it to the board yet — go back to Step 1.












Heading 1
Heading 2
Heading 3
Heading 4
Heading 5
Heading 6
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Block quote
Ordered list
- Item 1
- Item 2
- Item 3
Unordered list
- Item A
- Item B
- Item C
Bold text
Emphasis
Superscript
Subscript








