



You're three months out from HPE's mandatory March 2026 cutover from Classic Central to the new HPE Aruba Networking Central. Your team has a migration runbook from your global SI. But when you stress-test it against your actual config — the segmentation policies, the campus VRFs, the ClearPass integration with your AI workload tenancy — the runbook stops being a runbook and starts being a checklist of TODOs. You open a TAC case. Then a PSE engagement. And then a Redditor in r/ArubaNetworks says exactly what your network architect said in your last standup:
If that quote landed harder than it should have, you already know the question this article is trying to answer: when you're standing up HPE Aruba, Morpheus, or Private Cloud AI at enterprise scale, where does a global SI stop being enough — and what does a boutique dev partner actually do that a 130,000-person integrator can't?
KEY TAKEAWAYS
The HPE partner ecosystem is bimodal. Global SIs (DXC, Wipro, Infosys) cover horizontal scale; boutique dev partners increasingly own the validation-and-glue layer where TAC, PSE, and SI playbooks fall short.
AI workloads change network economics. Up to 20x higher east-west bandwidth on AI clusters and a Gartner-forecast 45% adoption of AI-driven network management by 2027 mean architectural decisions that used to be IT-ops are now strategy.
Platform churn is the real driver of boutique demand. Aruba Central cutover, Morpheus HA productization, and the post-Juniper-acquisition Instant On divestiture each surface integration gaps that scale-oriented SIs are slow to close.
The decision is per-workstream, not per-vendor. The same enterprise can rationally use a global SI for managed services and a boutique for cutover tooling — the wrong move is forcing a single partner across both jobs.
The Hidden Problem: Ecosystem Scale Doesn't Equal Ecosystem Fit
The market context is unambiguous. Enterprise wired and wireless LAN hit US$19.1 billion in 2023, up 20.4% YoY according to Gartner, and Gartner forecasts that more than 45% of large enterprises will use AI-enhanced, cloud-delivered network management for campus and branch by 2027, up from under 10% in 2022. IDC pegs AI-focused infrastructure spend at $18.6B in 2023, 39% YoY growth, with a $96.6B target by 2027. HPE has answered with a Private Cloud AI ecosystem and a Partner Program that — by HPE's own framing — is built to plug "best-of-breed vendors across horizontal and vertical use cases" into its AI and networking stack.
45%of large enterprises will use AI-driven network management by 2027 (Gartner)
But the scale story hides a fit problem. HPE's 2025 Global Ecosystem Partner Awards named Wipro (a $10.8B SI) as AI Partner of the Year, DXC Technology (~130,000 employees) as Networking Momentum Partner, and Infosys as Networking Partner of the Year. These firms can deliver. They cannot, by the physics of their delivery model, hand-tune a Central tenant for your specific segmentation model in the three weeks before a forced cutover. That's the gap boutique dev partners step into — and the gap CRN's reporting on the same awards quietly admits when it notes HPE is "increasingly looking to specialized partners for verticalization."
!
When 24% of major IT incidents in digital businesses are network-related (Gartner), the cost of a partner who can ship in HPE's release cadence isn't a procurement line item — it's an availability lever.
From the Field: Three Patterns That Decide the Partner Choice
Three forum threads from the last six months crystallize where the global-SI playbook stops working.
1. Platform cutovers nobody owns full
Beyond the Aruba Central cutover thread that opened this article, the r/ArubaNetworks license-budget thread from a network ops lead trying to produce a clean 2026 renewal forecast captures the side problem:
The thread doesn't tell us how the team ultimately reconciled their portal exports — the last comments are still trading workarounds.
This is the canonical boutique wedge. A custom Python pipeline that normalizes Aruba portal exports into auditable renewal forecasts is a two-week engagement. It is also exactly the kind of work no global SI will scope as a standalone deliverable.
2. HA productization for HPE's hybrid-cloud stack
On Dev.to, an engineer publishing on automating MySQL InnoDB cluster deployment for HPE Morpheus Enterprise HA (v8.1.0, Feb 2026) made the operational reality explicit:
Manual HA setup across Morpheus's four service tiers is silently brittle. Ansible-driven pre-flight automation is the kind of repeatable installer a boutique partner can productize for $80-150K and resell across an enterprise's regions. The big SI will do it once, for one customer, as part of a $4M managed-services contract.
3. Portfolio churn from the Juniper acquisition
The r/Juniper thread on the post-merger Instant On divestiture surfaces what every Field-CTO with a deployed Instant On footprint is now asking:
Migration-mapping across Aruba, Juniper Mist, and Instant On successors is unbiased-advisory work. A partner with a managed-services book of business with HPE has an obvious incentive problem; a boutique dev shop billing T&M does not.
The Pattern: Two Partner Archetypes, Two Different Jobs
The comparison below frames how the work actually splits.
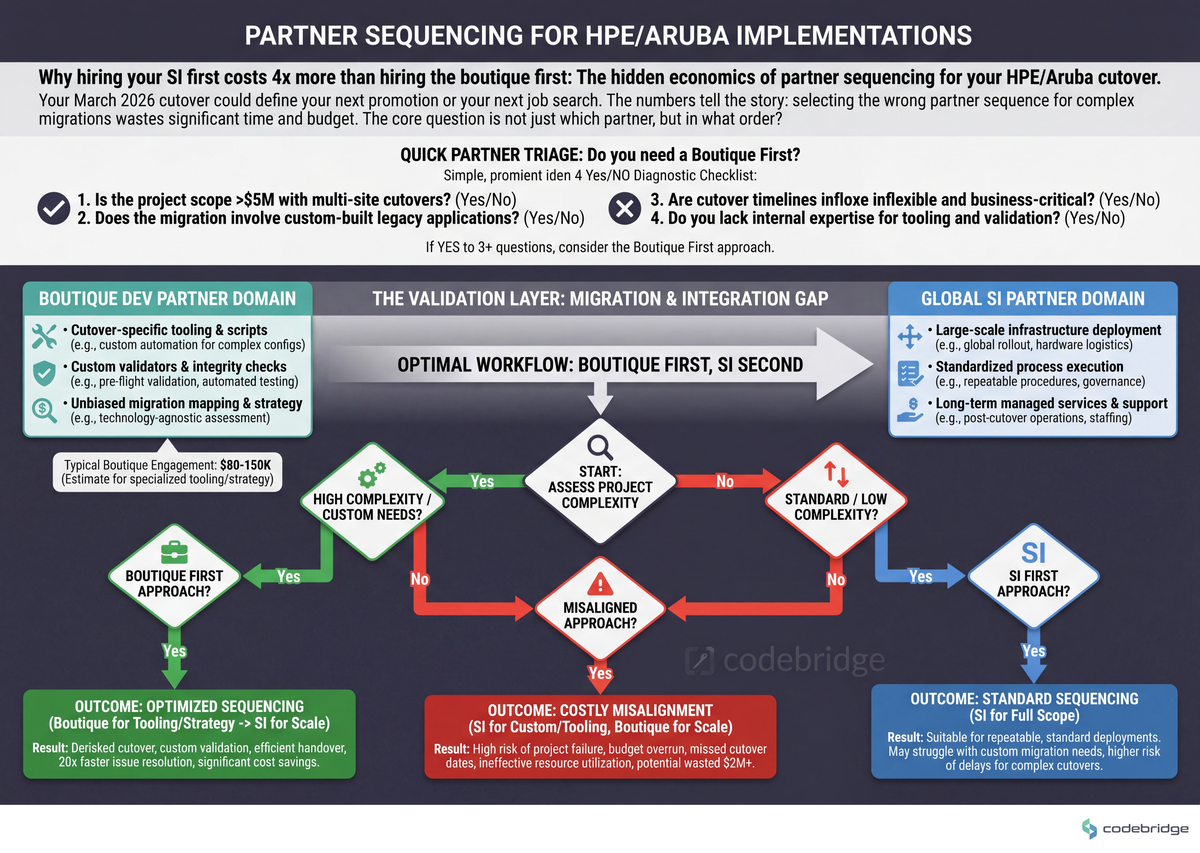
The right column shows the work boutique partners do that global SIs structurally cannot scope — cutover-specific tooling, custom validators, and unbiased migration mapping.
DimensionGlobal SI (DXC / Wipro / Infosys)Boutique dev partnerEngagement floor$1M+ managed services$50-300K T&M or fixed-bidTime to first commit4-12 weeks (statement of work, RACI, governance)1-2 weeks (signed MSA + scope doc)Best atMulti-region rollouts, 24x7 NOC, vendor managementCutover tooling, custom validators, Ansible/Terraform productization, AIOps glueWorst atPer-customer tenant tuning, niche HPE SKU edge casesSustained NOC, global L1 coverageWhere HPE TAC handoff landsInside an existing managed contractOutside — boutique fills the gap TAC won't own
From our work with enterprise networking teams: The pattern we see repeatedly is that the question "global SI or boutique?" is the wrong frame. The CTOs who get the most use out of HPE's ecosystem run both, sequenced: the boutique writes the validators, installers, and license-reconciliation scripts in the first two quarters of an HPE rollout, then the global SI inherits a clean, automatable estate to operate. Reversing the order — handing the SI a greenfield and asking them to produce the installers — is the most expensive mistake we see, because the SI's economics force them to bill hours for what should have been productized.
AI training clusters generate dramatically higher east–west bandwidth than traditional enterprise workloads. That's not a tuning problem — it's an architecture problem that lives at the seam between HPE Aruba CX fabrics, GPU-host tenancy, and your existing campus segmentation. A meaningful share of enterprise AI workloads still runs on private or hybrid infrastructure — meaning the seam is on-prem, where TAC's playbooks are thinnest.
Framework: A Four-Criterion Decision Tool
Use these four criteria to decide, per workstream, which partner archetype owns delivery. The matrix below maps them.
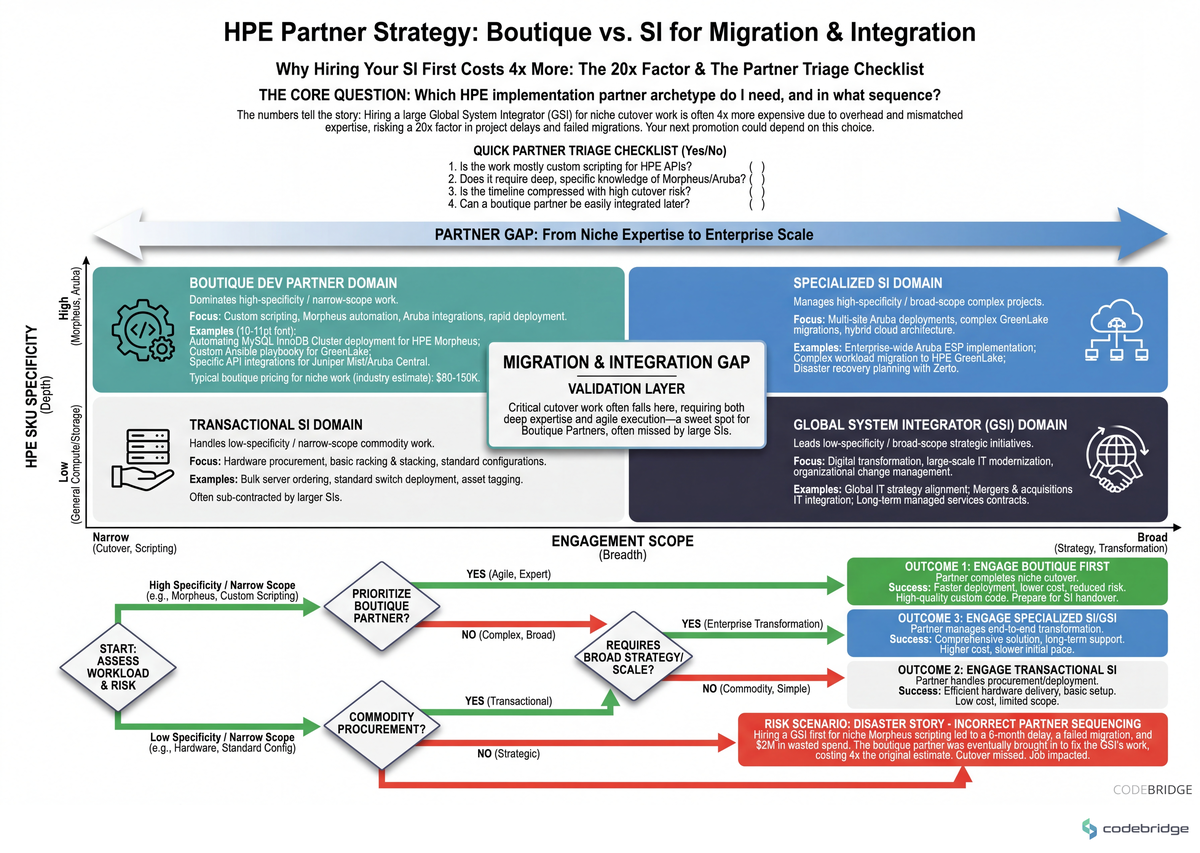
Two-axis matrix (engagement scope vs. HPE SKU specificity) showing which partner archetype wins each quadrant — boutique dominates the high-specificity / narrow-scope corner where most cutover work actually lives.
1. Apply the SKU-specificity threshold
If the workstream touches a specific HPE SKU release in a way TAC's published runbook doesn't cover (Central tenant migrations, Morpheus 8.1.0 HA, Aruba ClearPass + Private Cloud AI tenancy), boutique wins. The threshold: if your last TAC case took more than two escalations to close, your next workstream on the same surface area should not be scoped to a global SI. Gartner's AIOps research shows enterprises that automate the operations layer can cut incidents by up to 90% and MTTR by ~60% — but that automation has to be written by someone who's read the actual TAC ticket history.
2. Apply the productization test
Will the deliverable be reused across 3+ regions, business units, or tenant accounts within 12 months? If yes, scope it as a productized installer (Ansible role, Terraform module, validation harness) with a boutique. If no, hand it to the SI as managed services. The economic line: a productized installer that runs 20 times pays back at roughly 4x the cost of 20 SI-billed installs. If you can't articulate the reuse count, you're not ready to scope either way.
3. Apply the incentive-neutrality test
Migration mapping across Aruba, Juniper Mist, and Instant On successors must be done by a partner whose revenue does not depend on the destination. If your candidate partner has a managed-services book on the source platform, the answer's no. Boutique dev shops billing T&M pass this test by construction; global SIs with embedded HPE practice areas don't, and they shouldn't pretend otherwise.
4. Apply the cutover-clock test
If the workstream is bound to a vendor-imposed deadline inside the next 90 days (the Q1/Q2 2026 Aruba Central EoS being the canonical case), boutique is the only viable answer. Global SI sales cycles run 4-12 weeks before first commit; a 90-day deadline means SI staff arrive after the migration window closes. The Field-CTO move here is to pre-qualify two boutique partners on retainer specifically for cutover work, before any cutover is announced.
Verdict: Which Path to Pick
The opening case — a team three months from the Aruba Central cutover, with TAC and PSE unable to map a config — is the canonical boutique scenario by all four criteria above: high SKU specificity, low productization reuse, neutral incentive needed, hard deadline. The original Reddit thread doesn't tell us how that team resolved it. What we can say from the criteria: the team that solves it by Friday is the team that already had a boutique on retainer by Monday.
Pick the global SI path if: you need 24x7 NOC across more than three regions, your HPE estate is standardized on published reference architectures, and your engagement floor is above $1M annual.
Pick the boutique dev partner path if: you have a cutover-clock deadline inside 90 days, the workstream is narrow but SKU-specific, or you need an incentive-neutral migration map. For Field-CTOs in enterprise networking, this is the default for any new HPE Aruba Central, Morpheus HA, or Private Cloud AI workstream initiated in 2026.
Pick neither if: the work is fully covered by HPE's published runbook and your in-house team has done it before. Don't hire a partner to do what your senior network engineer can ship in a week.
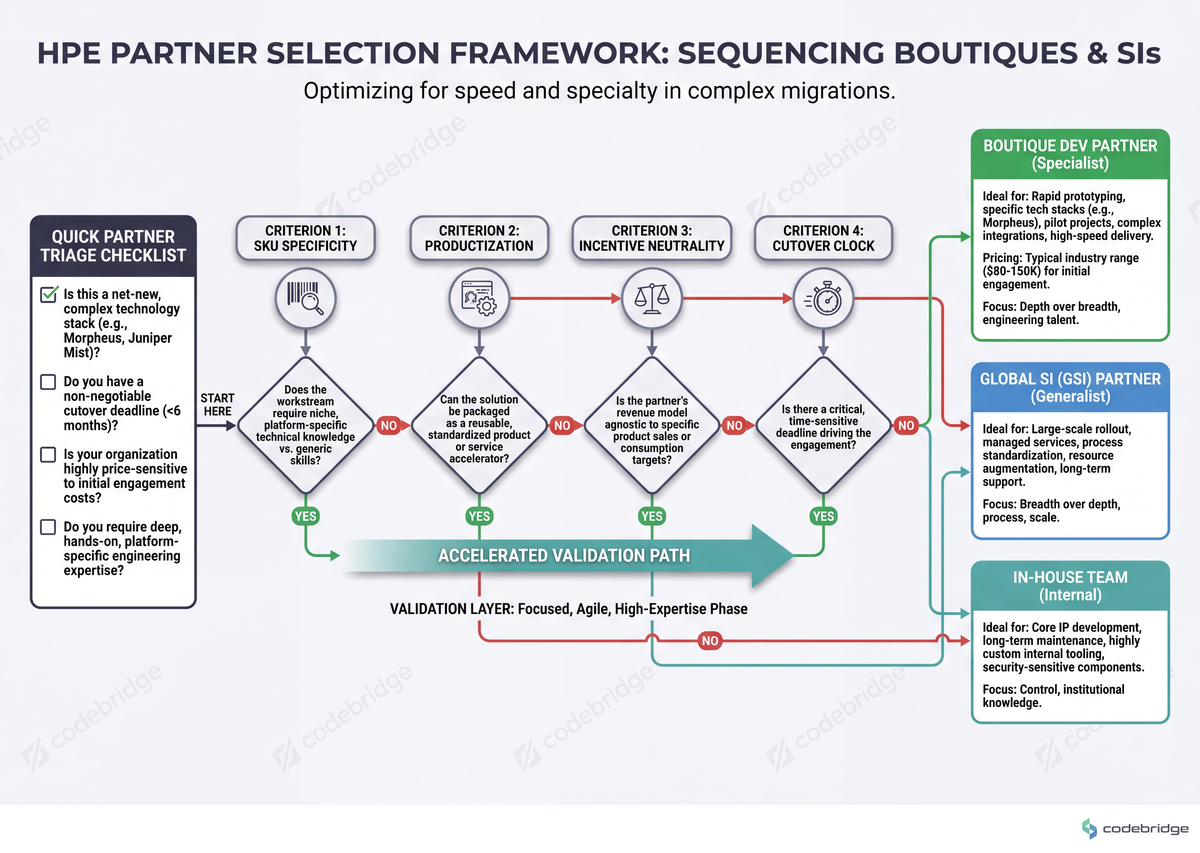
Decision tree that routes a workstream through the four criteria (SKU specificity, productization, incentive neutrality, cutover clock) to either global SI, boutique, or in-house.
The 30-minute artifact: open a spreadsheet, list every HPE-touching workstream on your roadmap for the next two quarters, and score each one against the four criteria. Any row with two or more "boutique" answers is a candidate for a scoped RFP this week — not next quarter, because the cutover clock is already running.
Need a partner who can ship inside a 90-day HPE cutover window?
Talk to our team about scoping a validator, installer, or migration map for your HPE Aruba, Morpheus, or Private Cloud AI workstream.
Diagnostic Checklist
Run these against your current HPE estate. Three or more "Yes" answers means you have at least one workstream miscast to the wrong partner archetype.
Has any HPE TAC case in the last 90 days required more than two escalations to close? Yes / No
Is your team treating the Q1/Q2 2026 Aruba Central EoS as "we'll get to it" rather than a scoped, owner-assigned workstream? Yes / No
Are you reconciling Aruba license renewals by hand from portal CSV exports rather than from a normalized internal forecast? Yes / No
Does your current SI's statement of work include the Morpheus 8.1.0 HA installer as a productized artifact (Ansible/Terraform), or as billable hours? Hours = Yes
If asked today, can your network architect name an unbiased advisor on Instant On successor migration paths whose revenue does not depend on the destination platform? No = Yes
Do your AI workload tenants share segmentation policy with general campus traffic, with no validator that catches east-west bandwidth contention at provisioning time? Yes / No
Has any HPE workstream on your 2026 roadmap been scoped without naming a specific deliverable reuse count (regions, BUs, tenants)? Yes / No
REFERENCES
Gartner — Market Share: Enterprise Network Equipment, Worldwide, 2023
Gartner — Forecast Analysis: Enterprise Network Equipment, Worldwide
Gartner — Innovation Insight for AIOps
Gartner — Manage Operational Risk for Digital Business With IT Service Continuity Management
IDC — Worldwide Artificial Intelligence Systems Spending Guide
McKinsey — The Economic Potential of Generative AI
Reddit r/ArubaNetworks — Classic Central going end of support Q1/Q2 2026
Reddit r/ArubaNetworks — Aruba Central License Budget 2026: Mission Impossible
Reddit r/Juniper — Will HPE's acquisition of Juniper lead to the divestiture of Instant On?
Dev.to — Automating MySQL InnoDB Cluster Deployment for HPE Morpheus Enterprise HA













Heading 1
Heading 2
Heading 3
Heading 4
Heading 5
Heading 6
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Block quote
Ordered list
- Item 1
- Item 2
- Item 3
Unordered list
- Item A
- Item B
- Item C
Bold text
Emphasis
Superscript
Subscript








