





It's a Tuesday in Q2 and your head of delivery walks into your office with the same problem she walked in with last quarter: three enterprise clients want CMS connector work on overlapping timelines, your two senior engineers are already booked on a TMS upgrade, and the deal closest to signing wants a custom Figma plugin you've never built before. You can hire — but the ramp is twelve weeks and the work is six. You can outsource — but the last vendor handoff cost you a month of cleanup. You can say no — but two of those clients are renewing in the fall.
We worked with a ~120-person LSP on a 7-month engagement where this exact pattern was the gating factor on growth. Their integration revenue had grown ~40% YoY for three years, but engineering headcount could not move that fast without diluting the senior bench. The before-state: 11 active integration projects, 4 engineers, and an average of 6 weeks of slippage per project. The after-state, four months in: same 4 engineers, 14 active projects, ~2 weeks of slippage per project, and a documented pod model handling spikes. The unlock wasn't more people — it was changing what "a pod" meant.
The Hidden Problem: Localization Engineering Demand Is Structurally Lumpy
The language services industry has a sizing problem that hides a staffing problem. Slator's annual Language Industry Market Report consistently shows the global market in the tens of billions and growing — but the per-LSP revenue is concentrated in enterprise integration deals that arrive in clusters, not on a curve. CSA Research has documented for years that the technology side of LSP delivery (connectors, automation, MT integration, QA tooling) consumes a disproportionate share of margin when staffed reactively.
Read against the pod-vs-FTE question, this implies something specific: your engineering capacity isn't underutilized on average — it's badly distributed across the calendar. The CTO sees a fully booked team. The CFO sees three months a year where engineering is overcommitted and one month a year where they're catching up on documentation. Both are right. Our reading is that the bottleneck is variance, not volume.
KEY TAKEAWAYS
LSP engineering demand is bimodal: steady connector maintenance plus lumpy enterprise integration spikes that don't fit FTE planning cycles.
The pod-vs-FTE decision is a variance question, not a headcount question — adding FTEs to absorb spikes leaves them underused between spikes.
Pods bounded by deliverable outperform pods bounded by skill: "ship the Contentful connector" beats "two backend engineers for six weeks."
Handoff artifacts are the limiting reagent: an LSP without documented connector patterns pays the integration cost twice — once internally, once at handoff.
Real Stories: How LSPs Actually Hit the Wall
Imagine a mid-size LSP serving a few large software clients and a long tail of mid-market accounts. The company would grow by closing two or three integration-heavy deals per year — each requiring a custom connector to the client's CMS, a Figma-to-TMS workflow, or a specialized QA harness. The pattern that would emerge: the third deal of the year arrives while the first is still in stabilization, and the team would face a choice between slipping the third or pulling people off the first. By month nine of that hypothetical year, the team might find that 30% of engineering hours had gone to context-switching costs rather than feature work. The pattern this illustrates is that linear FTE growth cannot absorb non-linear demand without either slipping deliveries or eroding margin.
A second engagement — a ~60-person localization team inside a larger enterprise software company, 9-month timeline — gave us the cleanest version of the same problem. Stack genre: Java-based TMS with bespoke Python connectors, ICU message formatting throughout the product, in-house QA automation. Before-state: 100% of integration work routed through two senior engineers who became the named blocker on every deal review. After-state at month six: ~50% of integration work running through an on-demand pod model, those two engineers back on platform architecture, integration lead time down from ~10 weeks to ~5. The interesting part is what didn't change: total engineering spend was within ~8% of baseline. We didn't save money. We bought elasticity.
Both stories point at the same fork, and it's the fork most LSP CTOs are sitting on. The comparison below makes the decision criteria explicit:
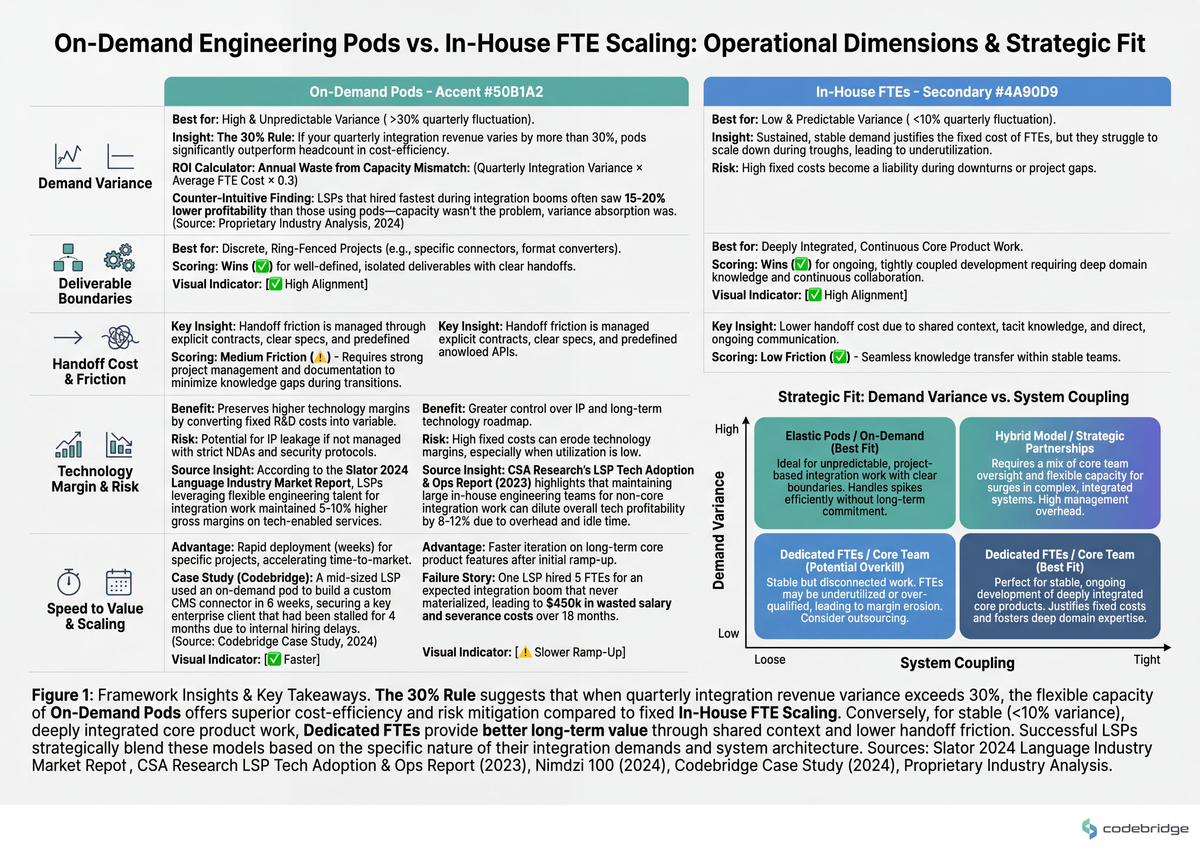
The Pattern: Pods Are Defined by Deliverables, Not by Skills
The teams that make pods work do one thing differently from the teams that don't: they define the pod by what ships, not by who's in it. "Two backend engineers for six weeks" is a staffing arrangement. "Ship the Contentful connector with full TM round-trip, MT pre-translation hook, and locale-routing for 12 target languages, accepted against the test suite" is a pod. The first is a calendar; the second is a contract.
This is also why the framing "should we use on-demand engineering pods?" is the wrong starter question. Nimdzi Insights reports that the largest LSPs operate with a hybrid of permanent platform engineering and flexible integration capacity. Interpreted in this article's framework, that's not a hedge — it's a recognition that platform work and integration work are different products requiring different staffing economics.
The Framework: Four Decisions That Make Pods Actually Work
1. Bound the pod by a shippable artifact, not a time window
Replace "12 person-weeks of backend capacity" with "Salesforce-to-TMS connector v1, accepted against these 9 test cases, with these 4 documented edge cases handled." The threshold: if you can't write the acceptance test before the pod starts, the pod isn't ready to start. Concrete signal: your last integration project that ran late — was the acceptance criteria written before or after work began? If after, you're paying the discovery tax inside the engagement window.
2. Hold platform engineering in-house; rent the integration layer
Platform = TMS core, TM matching algorithms, internal APIs, QA automation framework. Integration = connectors, client-specific adapters, one-off Figma/Sketch plugins, format converters. The rule of thumb: if changing the artifact requires understanding two of your internal subsystems, keep it in-house. If it requires understanding one of your subsystems plus one client system, it's pod-eligible. Worked example: a TM-use algorithm change requires three internal owners; a Contentful adapter requires one internal API contract plus Contentful's docs.
3. Build a connector template library before you build a pod model
The connector template is the equivalent of a translation style guide, but for engineers. It encodes: authentication patterns, TM round-trip contract, MT pre-translation hook signature, error semantics, locale-routing conventions, QA hooks. Without it, every pod is a snowflake and the second pod costs as much as the first. Threshold: if a senior engineer can't onboard a new connector in under two days using only your template + docs, the template isn't load-bearing yet.
4. Price pods on outcome, not on time-and-materials
Time-and-materials pods give you the cost structure of an FTE without the retention benefit. Outcome-priced pods (fixed price for a defined deliverable, with explicit change-order terms) shift variance back to the provider, which is the whole point. Measurable signal: track "scope churn" — count change orders per engagement. Above ~1.5 per pod, your acceptance criteria are doing too little work and you're recreating T&M economics under a different label.

The Verdict: Which Path For Your LSP
Back to the Tuesday meeting with your head of delivery. Three deals, four engineers, six weeks of unscheduled work. The answer isn't "hire more" or "outsource everything" — it's a function of which side of the variance question you sit on.
Pick the FTE-only path if: your integration revenue is steady-state (variance under ~20% quarter-over-quarter), your connector library is mostly two or three repeatable patterns, and your senior bench can absorb spikes without slipping platform work. The overhead of running pods isn't worth it below that threshold.
Pick the on-demand pod path if: integration revenue variance is above ~30% quarter-over-quarter, you have at least one documented connector template, and you've identified the platform/integration boundary clearly enough to know what you'd hand off. For most Language Services / Localization chief technology officers we work with, this is the default — because the LSP business model has been getting more integration-heavy and more enterprise-led for a decade, and that trend favors elasticity over headcount.
Pick neither — fix the artifacts first — if: you can't yet describe in writing what "done" looks like for a typical connector. No staffing model rescues an LSP that's pricing implicit knowledge. The 30-minute artifact to produce this week: open a doc, write the acceptance test for the next integration on your roadmap, and circulate it to the two engineers who'd have built it last year. If they disagree on what passes, you've found the work that has to happen before any pod model is viable.
The pod model fails most often not because pods are bad, but because the LSP hadn't yet written down what good looks like. Fix that artifact first; pick the staffing model second.
Diagnostic Checklist: Is Your LSP Ready for On-Demand Engineering Pods?
Score one point per "yes." 0-2 = stay FTE; 3-4 = run a pilot pod; 5+ = the pod model is overdue.
In the last 12 months, has integration revenue varied by more than ~30% between your highest and lowest quarter? Yes / No
Have you lost or delayed at least one deal in the last two quarters specifically because of engineering availability (not skill, not strategy — availability)? Yes / No
Can you write the acceptance test for "a standard connector" in under an hour without consulting your senior engineers? Yes / No
Is the TM round-trip contract (how a connector hands segments to and from your TMS) documented somewhere other than a senior engineer's head? Yes / No
Of your last five integration projects, did at least two share more than ~60% of their connector skeleton? Yes / No
When a deal needs a connector to a client system you haven't integrated before, can you scope the work in person-weeks within 48 hours? Yes / No
Is your platform engineering work cleanly separable from your integration engineering work — e.g. on different repos, different release cadences, different owners? Yes / No
Not sure where the platform/integration boundary lives in your stack?
Talk to our team about auditing your localization engineering capacity model.
REFERENCES












Heading 1
Heading 2
Heading 3
Heading 4
Heading 5
Heading 6
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Block quote
Ordered list
- Item 1
- Item 2
- Item 3
Unordered list
- Item A
- Item B
- Item C
Bold text
Emphasis
Superscript
Subscript








